
AI Compass前沿速览:Gemini 3、Grok 4.1、GPT-5.1、千问、Lumine
AI Compass前沿速览:Gemini 3、Grok 4.1、GPT-5.1、千问、Lumine-3D开世界AI智能体
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:*******************************************
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
Gemini 3 – 谷歌
Gemini 3是谷歌最新推出的新一代多模态理解与推理AI模型,被誉为全球最先进的模型。它具备强大的推理能力,并在LMArena Leaderboard等多项基准测试中刷新记录,以高分登顶。Gemini 3支持文本、图像、视频等多种模态输入,能够处理复杂问题并提供可靠答案,同时引入了“深度思考模式”以进一步提升解决问题的能力。该模型旨在通过先进的智能、代理能力和个性化,使AI对每个人都真正有帮助。
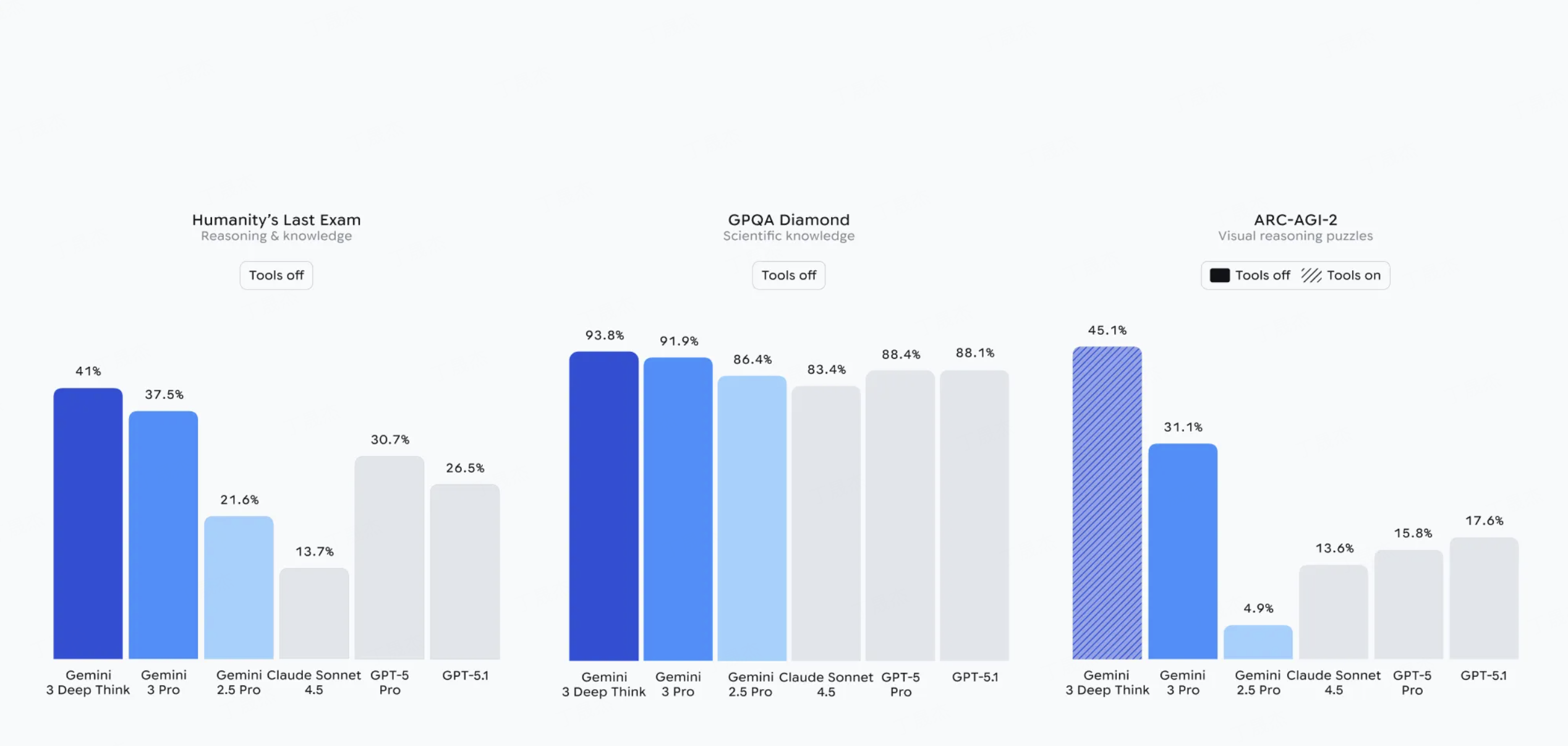
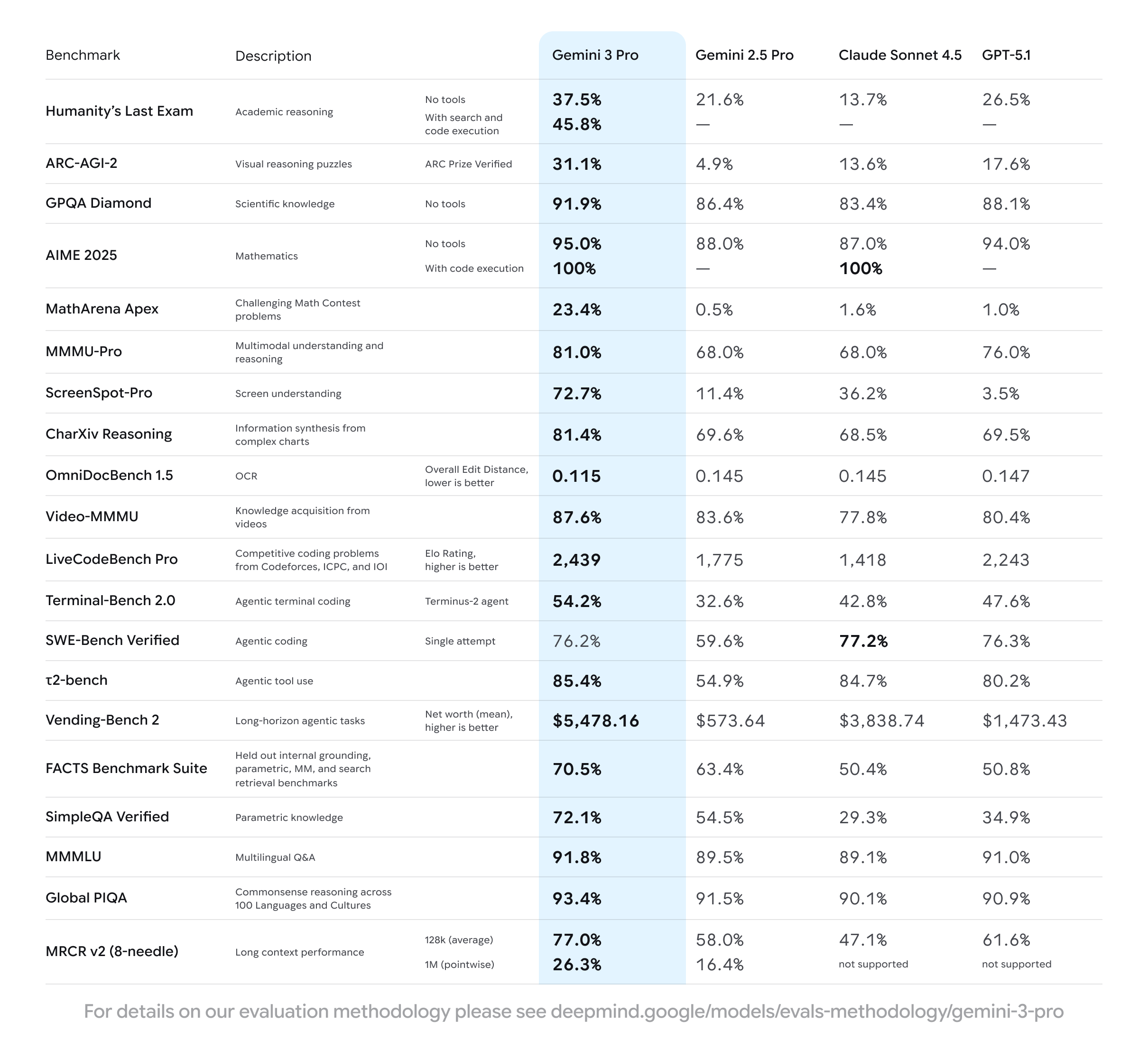
核心功能
- 多模态处理: 支持文本、图像、视频等多种输入模式的理解和融合。
- 强大推理能力: 具备卓越的指令遵循能力和逻辑推理能力,能处理复杂查询。
- Agentic能力: 增强的工具使用和代理功能,支持多步骤任务的规划与执行,能够构建智能个人AI助手。
- 生成式UI: 在搜索中提供生成式交互界面,动态生成沉浸式视觉布局、交互工具和模拟。
- 创意内容生成: 能够生成高质量的诗歌、故事、游戏代码等创意内容。
- 复杂问题解决: 通过引入“深度思考模式”提升了解决复杂问题的能力。
- 开发生态支持: 可在Google AI Studio、Vertex AI、Gemini CLI等平台以及Cursor、GitHub等第三方工具中使用,支持零样本生成和复杂提示处理。
- 数据处理优化: 能准确转录多小时多语言会议并识别发言人,从低质量文档图片中高效提取结构化数据。
技术原理
- 统一多模态架构: 模型底层采用统一架构,实现对不同数据模态(文本、视觉、音频)的无缝理解和融合,而非简单拼接。
- 深度Transformer网络: 可能采用高度优化的Transformer架构,通过注意力机制捕捉跨模态的长距离依赖和复杂关联。
- 自回归生成与预测: 在内容创作和对话生成中,利用自回归方式逐步生成高质量、连贯且符合上下文的内容。
- 强化学习与规划: Agentic能力的实现可能结合了强化学习技术,使模型能够进行多步决策、工具调用和任务规划。
- 先进的推理引擎: “深度思考模式”暗示了模型内部包含更复杂的推理模块,可能涉及多轮次内部思考或规划树搜索等机制来提升问题解决的准确性和鲁棒性。
- 高效的数据并行与模型并行: 为支持大规模模型训练和部署,可能采用了先进的分布式训练策略和高效的内存管理技术。
- 生成对抗网络/变分自编码器: 在生成式UI和创意内容生成方面,可能融入了生成模型(如GANs或VAEs)的先进思想,以产生多样化和高质量的输出。
应用场景
-
学习与教育: 生成交互式学习工具,辅助高效获取和理解新知识。
-
软件开发与编程: 作为强大的编程助手,支持代码生成、调试,并提升开发效率(“vibe coding”和“agentic coding”)。
-
企业效率提升: 自动化会议纪要、语言翻译、文档数据提取与分析。
-
内容创作与营销: 辅助撰写文案、故事、脚本,甚至游戏和营销内容。
-
智能搜索与知识管理: 在谷歌搜索中提供智能、可视化的生成式UI,实现更高效的信息检索和整合。
-
个人助手与智能体: 构建能够理解用户意图并执行复杂多步骤任务的个人AI助手。
-
旅游与服务: 提供个性化旅行推荐,并能动态生成交互式行程规划界面。
-
概念解释与可视化: 自动生成图表、动画或模拟,以直观易懂的方式解释复杂概念。
Grok 4.1 发布,带来更智能的 AI 助手
Grok 4.1 是由 xAI 公司发布的最新人工智能模型,在前一代 Grok 4 的基础上进行了显著提升。该模型旨在作为一个免费的AI助手,致力于追求真实性和客观性。Grok 4.1 在通用能力、情感智能和创意写作方面表现出色,并被宣传为全球最智能的模型之一。
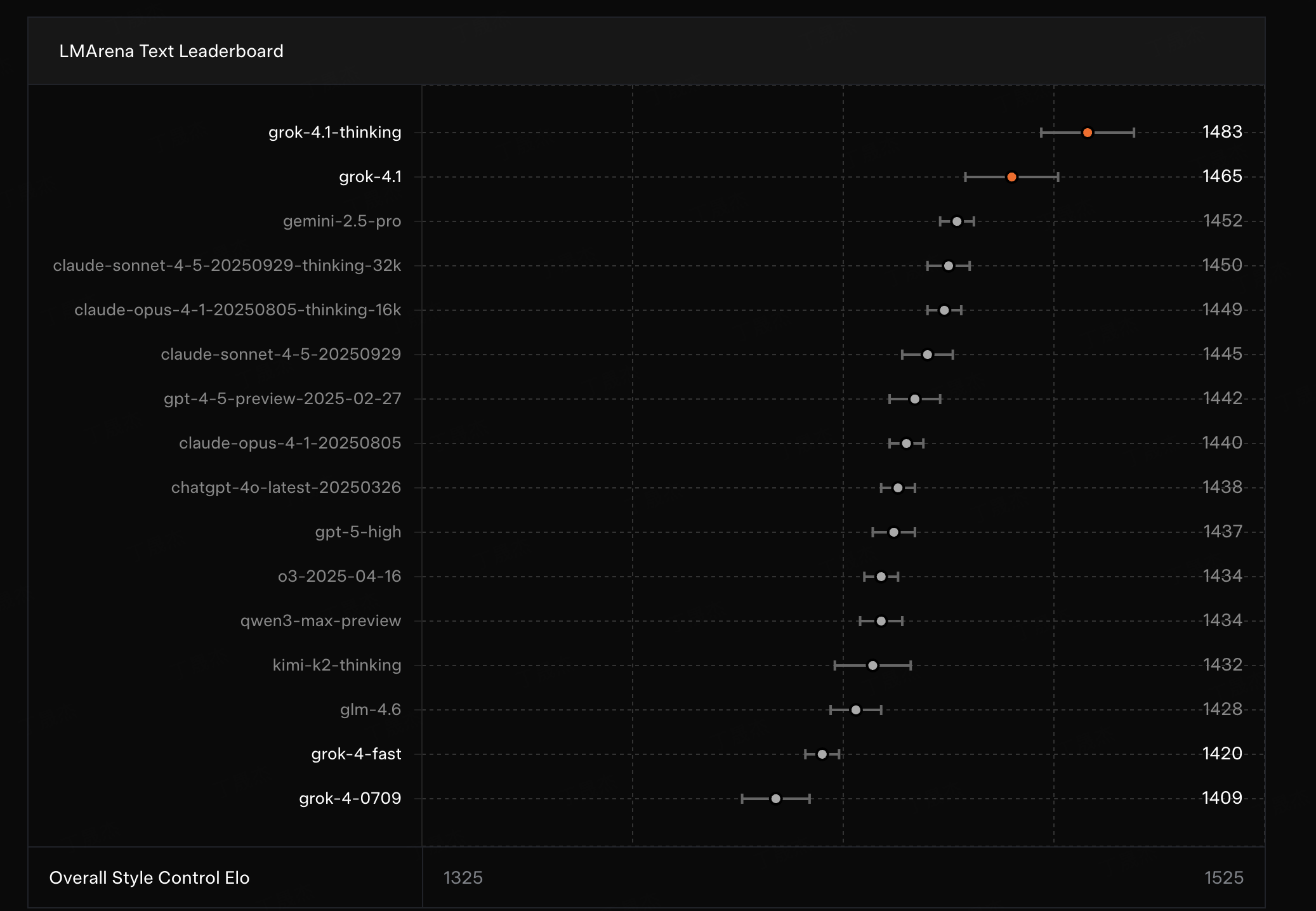
核心功能
- 通用能力与智能提升:在多项能力上实现显著进步,尤其体现在复杂推理方面。
- 情感智能与创意写作:具备出色的情感理解和生成能力,以及高级的创意文本创作功能。
- 实时搜索与分析:提供实时信息搜索、图像生成和趋势分析功能。
- API 访问与长上下文支持:通过 API 提供服务,支持 128K 的超长上下文处理能力。
- 原生工具使用:支持模型与外部工具进行原生交互,扩展其功能边界。
- 语音模式与视觉理解:Grok 4 具备语音模式,能够解释通过摄像头看到的内容。
技术原理
Grok 4 系列模型的核心技术原理包括:
- 强化学习规模化 (Scaling Up Reinforcement Learning):通过大规模强化学习训练,显著提升模型的性能和推理能力。
- 原生工具集成 (Native Tool Use):模型能够直接调用和使用外部工具,增强其解决问题的能力。
- 复杂推理能力:在 USAMO'25 和“人类最后考试”等高难度测试中表现出色,展现了卓越的复杂推理和问题解决能力。
- 长上下文处理:API 支持 128K tokens 的上下文窗口,表明其在处理长篇文本和保持连贯性方面有先进技术。
应用场景
- 智能助理与信息查询:作为个人或企业智能助手,提供实时搜索、问题解答和信息概括。
- 内容创作与编辑:应用于创意写作、文案生成、剧本创作等领域。
- 数据分析与洞察:进行趋势分析,从大量数据中提取有价值的洞察。
- 应用开发:通过 API 接口,开发者可将 Grok 的智能集成到各类应用和服务中。
- 多模态交互:结合语音模式和视觉理解,支持更自然、多样的人机交互场景。
- 教育与研究:辅助学生和研究人员进行学习、解决复杂问题和进行逻辑推理。
SIMA 2 – 谷歌DeepMind推出的最新一代AI智能体
SIMA 2 (Scalable Instructable Multiworld Agent 2) 是DeepMind推出的一款通用型AI智能体,它整合了Google的Gemini模型,旨在提升AI在3D虚拟环境中的交互、推理和自主学习能力。相较于前代SIMA,SIMA 2从简单的指令遵循者进化为能够理解复杂指令、进行多步任务规划、并能与用户进行自然语言交流的交互式游戏伴侣,代表了AI在迈向通用人工智能(AGI)方面的重要进展。
核心功能
- 复杂任务理解与执行: 能够理解并分解长串、复杂的指令,执行多步、空间复杂的任务,例如在虚拟世界中导航、寻找物品并完成特定操作。
- 交互式对话与推理: 不仅能遵循指令,还能与用户进行自然语言交流,回答问题,并对其行为和环境进行推理。
- 环境自适应与泛化: 能够在未曾见过的虚拟环境中执行任务,并能根据自身经验进行自我改进,展现出强大的泛化能力。
- 空间感知与导航: 具备高级的空间推理能力,能构建环境的“心理地图”,识别地标,规划高效路径,而非盲目探索。
- 语义理解与上下文推理: 能够处理指令中的模糊性和不精确性,通过上下文理解进行合理推断,弥补人类沟通中的信息缺失。
技术原理
SIMA 2的核心技术原理在于将大型语言模型(LLM)Gemini(特别是Gemini 2.5 flash-lite模型)的强大语言理解和推理能力与多模态感知及动作执行相结合。它通过多世界数据训练,使其具备广泛的通用能力,能够处理多样化的虚拟环境。其工作流程涉及:
- 指令解析: 利用Gemini模型深度理解用户输入的自然语言指令,包括长指令、复杂指令以及带有模糊信息的指令。
- 目标分解与规划: 将高层目标分解为一系列可执行的子任务和动作序列。
- 多模态感知: 实时处理虚拟世界中的视觉、空间等信息。
- 决策与行动: 根据解析出的目标和环境感知,结合自身的推理能力,在3D虚拟环境中生成并执行相应的操作。
- 自我学习与改进: 具备从经验中学习和自我改进的能力,不断优化其在各种任务中的表现。 这种架构使其能够从单一指令遵循者转变为一个能够思考、沟通和进化的智能体。
应用场景
- 通用游戏AI: 作为智能游戏伴侣,在各种3D虚拟游戏中与玩家互动、协助完成任务。
- 虚拟世界探索与自动化: 在元宇宙、虚拟训练环境或数字孪生中进行复杂任务的自动化执行和探索。
- 机器人与具身AI研究: 为未来更通用的机器人和具身AI系统提供研究基础,使其能在真实世界中进行更复杂的交互和操作。
- 教育与模拟训练: 在模拟环境中进行高度逼真且自适应的教学和训练。
- 辅助设计与开发: 在虚拟设计和开发环境中,作为智能助手帮助用户完成复杂的建模和测试任务。
GPT-5.1 – OpenAI最新推出的升级版AI模型
GPT-5.1是OpenAI对GPT-5系列大型语言模型的升级版本,旨在显著提升AI的智能性、沟通能力和用户体验。该版本包含两个主要模型:GPT-5.1 Instant和GPT-5.1 Thinking,分别侧重于日常对话和复杂推理任务,并支持个性化定制ChatGPT的响应风格。此升级模型已逐步向付费用户和API开发者推出,并计划最终成为默认模型。
核心功能
- 双版本模型: 提供GPT-5.1 Instant(更自然、适合日常对话,遵循指令,提供有趣回答)和GPT-5.1 Thinking(专注于复杂推理,更精确调整思考时间,处理复杂任务更详尽,简单任务更快速)。
- 性能大幅提升: 在动态评估中超越GPT-4.1和GPT-5,运行速度比GPT-5快2-3倍。
- 令牌效率优化: 在工具密集型推理任务中,使用的令牌数量大约是主要竞争模型的一半,显著降低成本和提高效率。
- 高级推理与工具使用: 增强了并行工具调用能力(提高端到端任务完成速度)、提升了编码任务表现、强化了指令遵循能力以及优化了搜索工具的使用(包括API平台中的网页搜索功能)。
- 个性化定制: 支持用户自定义ChatGPT的对话语气和风格,以满足不同的应用场景和个人偏好。
技术原理
GPT-5.1在GPT-5的基础上进行了深度优化,其核心技术原理体现在:
- 自适应推理机制: 模型能够根据任务的复杂度和需求,智能地调整其思考和处理时间,从而在保证效率的同时提高回答的准确性。
- 高效参数利用与压缩: 通过改进模型架构和训练算法,实现了更高的令牌效率,意味着在处理相同任务时能用更少的计算资源和数据量。
- 强化多模态集成: 虽然具体细节未完全披露,但作为GPT-5的升级,其在文本和视觉等多模态处理方面应有进一步的强化和协同能力。
- 增强的工具集成与编排: 显著提升了模型调用外部API和工具(如网页搜索、代码执行器等)的并行处理能力和准确性,实现了更流畅、更复杂的任务自动化。
- 稳健的安全缓解策略: 沿用了GPT-5系统卡中描述的全面安全缓解措施,确保了模型在更强大能力下的安全性和鲁棒性。
应用场景
-
智能对话与客服: 作为ChatGPT的核心模型,提供更智能、更人性化的日常对话和客服支持。
-
复杂问题解决与研究: 在科学研究、金融分析、市场调研等需要深度逻辑推理和数据整合的领域提供强大支持。
-
软件开发与编程辅助: 辅助开发者进行代码生成、调试、代码审查以及自动化脚本编写。
-
企业级自动化与工作流: 在AI保险BPO(业务流程外包)等领域,通过AI代理人提升业务处理速度和准确性,优化运营效率。
-
个性化内容创作: 生成创意文本、营销文案、教育材料等,并可根据用户需求定制输出风格。
-
教育与学习平台: 作为智能教学辅助平台,提供高效的备课工具和定制化的学习伴侣。
-
数据分析与决策支持: 能够快速处理和分析大量信息,为商业决策提供洞察和建议。
-
技术论文:https://cdn.openai.com/pdf/4173ec8d-1229-47db-96de-06d87147e07e/5_1_system_card.pdf
千问APP
千问APP是阿里巴巴旗下的官方AI助手,由其最强大的Qwen大模型驱动,旨在为用户提供智能化的工作、学习和生活辅助。该APP前身为“通义”APP,经品牌升级后,致力于成为个人AI领域的领先产品,全面对标国际先进AI应用。
核心功能
- 对话问答: 基于超大规模模型提供智能、结构化的问答服务,尤其擅长专业领域问题,并主动推荐图表、视频等辅助理解。
- 智能写作: 支持多裁体写作需求,能够根据用户指令生成广告语、新闻稿、报告、小说等各类文案,提高文本创作效率。
- 全能相机: 具备图像识别、以图搜图以及强大的视觉推理能力,能够对实物进行准确识别和深度思考。
技术原理
千问APP的核心技术依托于阿里巴巴自研的Qwen(通义千问)大模型。该模型融合了闭源与开源优势,具备“聪明会思考”的认知能力,并通过大规模预训练和持续优化,实现了多轮对话、逻辑推理和多模态理解等复杂功能。其视觉推理能力基于深度学习和计算机视觉技术,赋能相机识别与分析。
应用场景
- 个人助手: 作为个人AI助手,提供日常咨询、问题解答、信息获取等服务。
- 办公学习: 辅助撰写邮件、报告,生成研究报告和PPT,进行知识问答和学习辅导。
- 内容创作: 自动生成各类文案、创作小说后续内容,提升内容生产效率。
- 生活服务: 未来计划集成地图、外卖、订票、购物、健康等多种生活场景服务,实现“会办事”的AI生活入口。
- 多语言交互: 支持中文、英文、日文等多种语言进行自然、流畅的多轮对话。
蚂蚁灵光App
蚂蚁灵光App是蚂蚁集团发布的一款全模态通用AI助手,旨在通过自然语言在移动端30秒内快速生成可编辑、可交互、可分享的小应用。它作为蚂蚁集团AGI(通用人工智能)战略的产品级探索,致力于将复杂的应用开发过程简化,实现AI应用的普及化落地,目前已在安卓和苹果应用商店上线。
核心功能
- 灵光对话: 提供生动高效的多模态对话体验。
- 灵光闪应用: 用户通过自然语言指令,可在30秒内即时生成轻量级、可分享、具备动态互动能力的专属应用(App),并能直接调用大模型等后端能力,彻底改变传统App的获取和使用方式。
- 灵光开眼: 结合手机摄像头和AI技术,实现对现实世界物体的实时、准确识别与分析,包括金融财报、学术论文等复杂信息,具备“具身智能”的初步探索能力。
- 全模态内容生成: 支持3D数字模型、音频、视频、图表、动画、地图等多种模态的信息输出。
技术原理
蚂蚁灵光App基于蚂蚁集团的AGI(通用人工智能)战略,是业内首个实现全代码生成多模态内容的AI助手。其核心技术原理包括:
- 多智能体协作 Agentic 架构: 底部构建的多智能体协作架构能够自动理解用户意图,以代码为核心,实时调度影像、3D、动画等不同领域的专业AI智能体进行协同工作。
- 大模型支持: 能够直接调用大模型等后端能力,为应用生成和内容理解提供强大的智能支撑。
- 信息美学: 追求“好看又好懂”的设计哲学,将复杂信息结构化、个性化、可视化,确保内容输出高度美观、沉浸式、可交互。
- 具身智能探索: 利用移动设备作为具身智能的载体,通过摄像头实现对物理世界的感知和分析能力。
应用场景
- 个性化应用生成: 根据用户需求快速生成如运动健身计划、旅行规划、网络热梗解析等各类定制化小应用。
- 智能信息交互: 在对话中输出3D模型、音视频、图表、动画、地图等全模态内容,提升信息交流的效率和生动性。
- 视觉智能识别与分析: 实时识别物体,分析复杂的金融财报、解读学术论文核心要点,甚至进行相似物品的“找不同”分析。
- 内容创作与效率工具: 帮助用户更高效地获取、理解和创造内容,将复杂任务转化为简单易用的AI工具。
2.每周项目推荐
Lumine – 字节跳动推出的3D开放世界通用AI智能体
Lumine是字节跳动推出的通用AI智能体,旨在3D开放世界环境中实现实时感知、推理和行动。它能够像人类一样与复杂多变的虚拟世界进行交互,是首个能够完成数小时长复杂任务的通用智能体,展现出跨游戏的零样本泛化能力。
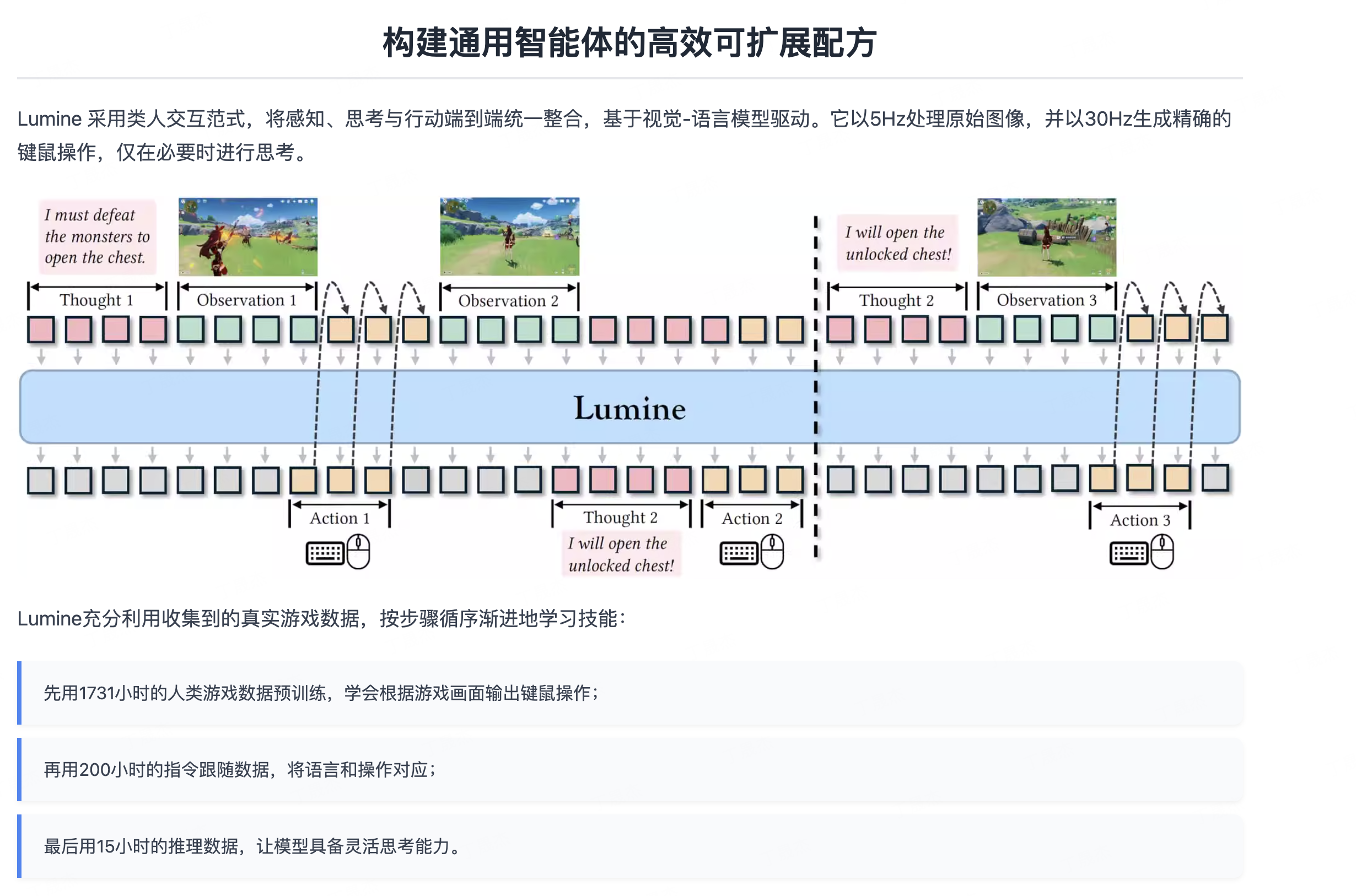

核心功能
- 实时感知与理解: 能够实时感知3D开放世界环境中的视觉信息。
- 自主推理与决策: 基于感知信息进行高级推理,规划并执行复杂任务。
- 类人交互与行动: 通过“视觉推理”与游戏进行交互,执行包括探索、战斗、解谜和NPC互动等多种操作。
- 任务自动化与完成: 能够高效完成长时序、多步骤的复杂任务,例如在《原神》中完成主线剧情。
- 零样本跨游戏泛化: 无需针对特定游戏进行微调,即可在不同3D开放世界游戏中展现通用能力。
技术原理
Lumine基于视觉-语言模型(VLM)构建,具体采用了Qwen2-VL-7B-Base模型。其核心技术原理包括:
- 视觉-语言模型(VLM): 作为核心认知引擎,使Lumine能够理解图像和文本信息,并在此基础上进行高级语义理解和推理。
- 类人交互范式: 采用一种模拟人类感官和认知过程的交互方式,通过观察游戏画面(视觉输入)和理解任务指令(语言输入)来驱动决策和操作。
- 四层架构设计: 受人脑记忆机制启发,包含代理层等结构,提供持久、可检索的记忆能力,支持长时序任务的连贯执行。
- 视觉推理机制: 区别于传统依赖游戏内部数据的AI,Lumine通过分析游戏画面的像素信息进行环境理解和状态判断,从而实现与游戏的互动。
应用场景
-
3D开放世界游戏: 自动化完成游戏内的探索、战斗、资源收集、任务递交、解谜以及NPC交互等各类任务,提升游戏体验或用于游戏测试。
-
虚拟世界模拟与测试: 在复杂的虚拟环境中进行智能体的行为模拟和性能测试。
-
通用人工智能研究: 作为构建更强大、更通用AI代理的开放平台和“食谱”,推动通用AI在复杂环境中的发展。
-
教育与培训: 在虚拟教学环境中创建智能引导或陪练角色。
-
arXiv技术论文:https://arxiv.org/pdf/2511.08892
InfinityStar – 字节跳动推出的高效视频生成模型
InfinityStar是由字节跳动(FoundationVision)推出的一款高效视频生成模型。它旨在通过统一的时空自回归框架,实现高分辨率图像和动态视频的快速合成,是视频生成领域的重要进展。
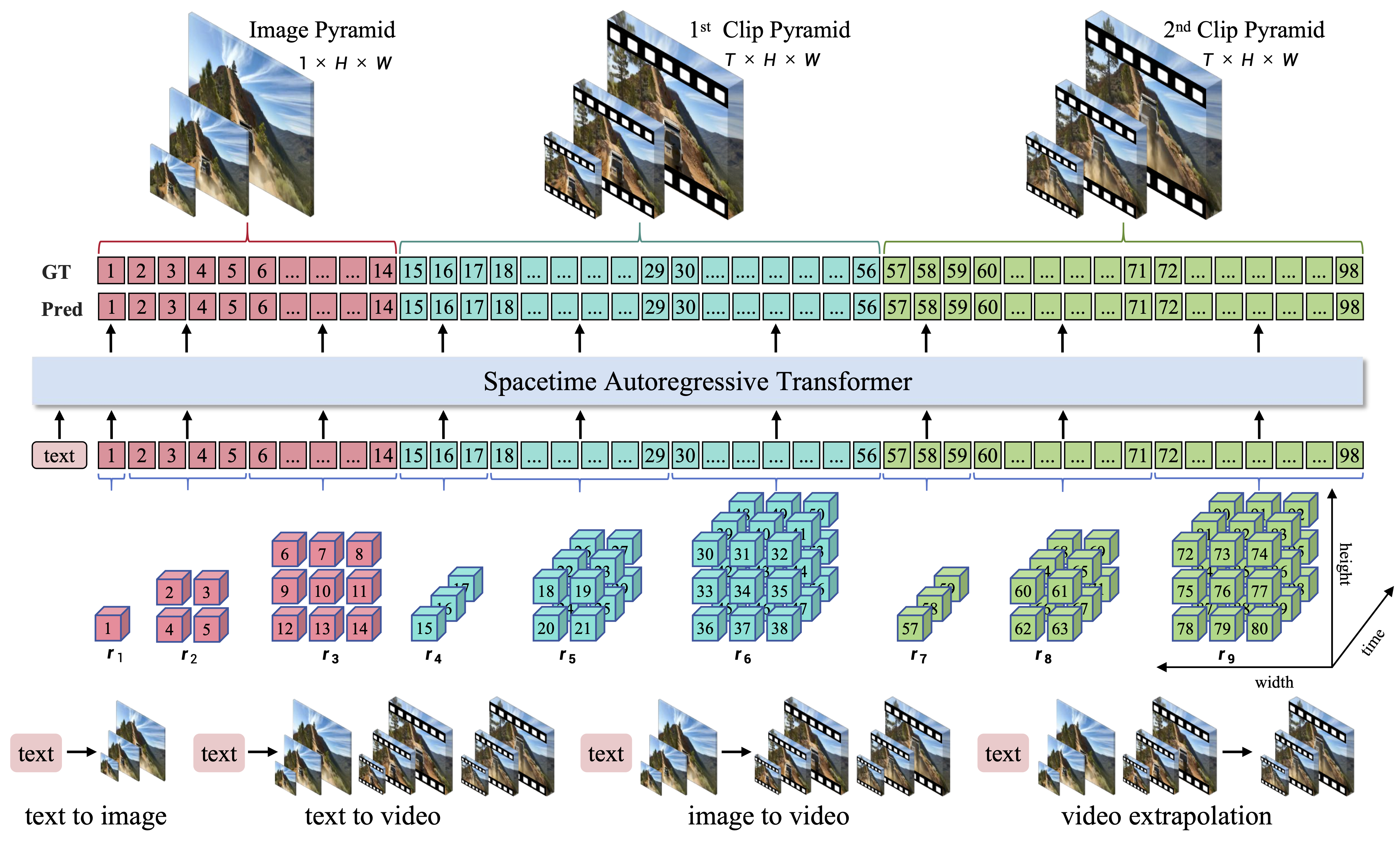
核心功能
- 高分辨率图像生成: 能够生成细节丰富的高质量图像。
- 动态视频合成: 具备快速生成流畅、逼真动态视频的能力。
- 统一的时空自回归框架: 将图像和视频生成整合到统一的模型架构中。
技术原理
InfinityStar采用了统一的时空自回归框架(unified spatio-temporal autoregressive framework)。其核心技术包括时空金字塔结构(spatio-temporal pyramid structure),通过将视频分解为不同尺度的时空信息进行处理和合成,从而优化生成效率和质量。这种架构使其能够同时处理时间和空间维度上的依赖关系,确保视频内容的连贯性和动态性。
应用场景
-
内容创作与媒体生产: 快速生成高质量视频素材,应用于影视后期、广告制作、短视频创作等。
-
虚拟现实与游戏开发: 生成逼真的虚拟场景和角色动画,提升沉浸式体验。
-
计算机视觉研究: 作为基准模型或工具,推动视频生成、预测及理解等领域的研究。
-
数字人与虚拟偶像: 驱动虚拟形象的动态表现和互动。
-
HuggingFace模型库:https://huggingface.co/FoundationVision/InfinityStar
SmartResume – 阿里开源的智能简历解析工具
SmartResume是阿里巴巴开源的一款智能简历解析工具。它旨在解决传统简历处理中数据不完整、非结构化等问题,通过自动化技术对不同格式的简历进行高效、准确的解析和结构化处理。
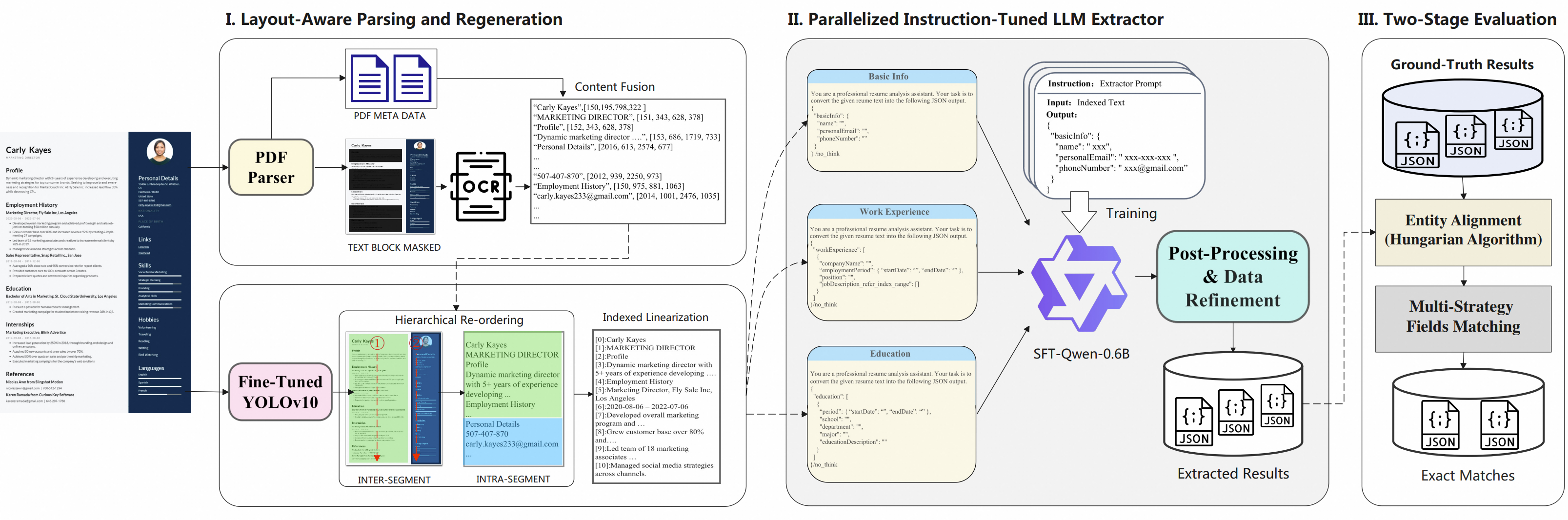
核心功能
- 多格式简历解析: 支持PDF、图片、Word等多种主流简历文件格式的摄入和处理。
- 文本信息提取: 能够从简历中进行OCR文本提取和PDF元数据解析。
- 版面检测与结构化: 实现简历版面检测,并利用大型语言模型(LLM)进行智能结构化处理,将非结构化数据转化为可用的结构化信息。
- 人才信息管理: 为招聘方提供标准化、可验证的人才数据,助力人才发现、招聘和管理。
技术原理
SmartResume的核心技术原理结合了多种先进的AI和数据处理方法:
- 光学字符识别 (OCR): 用于从图片和扫描的PDF中提取文本信息。
- PDF元数据解析: 直接从PDF文件中获取结构化和非结构化数据。
- 版面检测 (Layout-aware parsing): 通过计算机视觉技术识别简历的布局结构,区分不同信息区域(如个人信息、教育背景、工作经历等)。
- 大型语言模型 (LLM) 智能结构化: 运用先进的自然语言处理技术,对提取的文本信息进行语义理解、实体识别和关系抽取,从而实现简历内容的智能结构化。
应用场景
-
企业招聘: 帮助企业高效筛选和管理海量简历,提高招聘效率和准确性。
-
人才管理系统: 作为人力资源管理系统(HRM)或招聘管理系统(ATS)的后端模块,实现简历数据的自动化录入和标准化。
-
职业服务平台: 为求职者和招聘机构提供简历数据标准化和认证服务,确保信息的真实性和可靠性。
-
数据分析: 将简历信息结构化后,可用于人才画像分析、市场趋势研究等大数据应用。
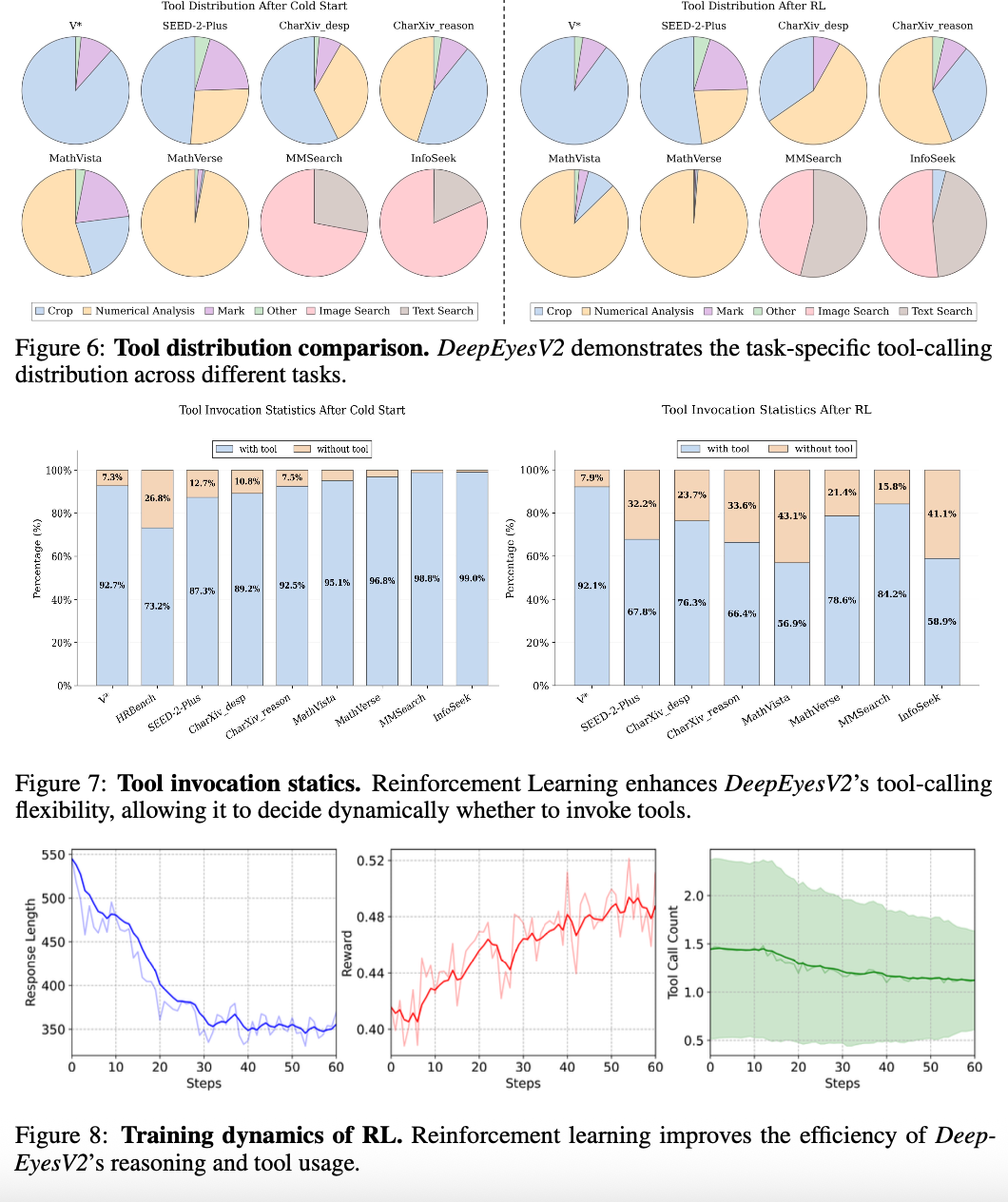
DeepEyesV2 – 小红书开源的多模态智能体模型
DeepEyesV2 是由小红书团队开源的多模态智能体模型,它扩展了前一代 DeepEyes 模型,专注于实现更强大的工具调用和多模态推理能力。该模型能够理解图文信息,并通过将代码执行和网络检索作为互补且可交错的工具,整合到单一的推理轨迹中,从而有效处理复杂的多模态任务。
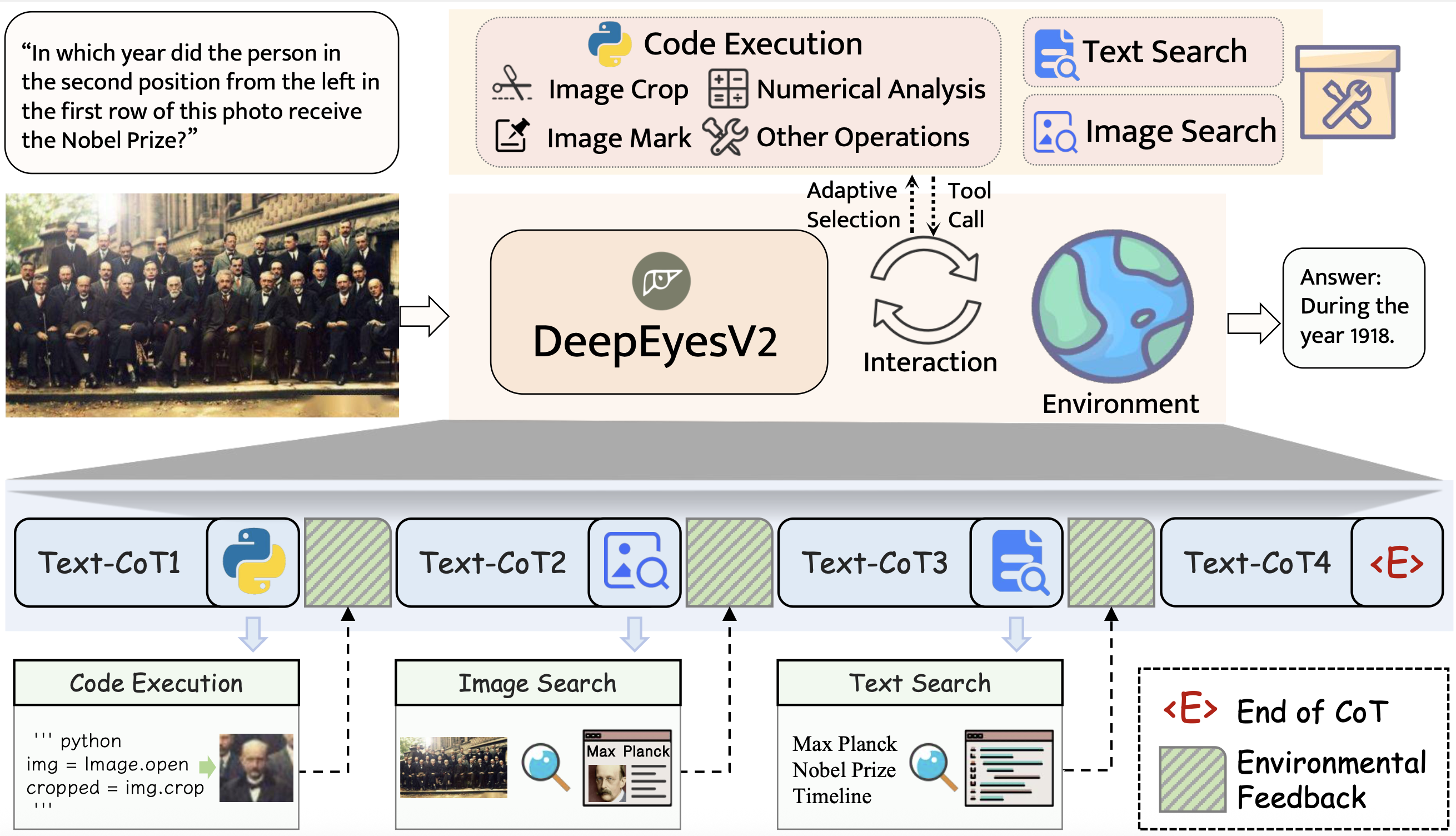
核心功能
- 多模态理解与推理: 能够深度理解图像和文本信息,并在此基础上进行高级推理。
- 工具调用能力: 支持主动调用外部工具,包括程序代码执行环境和网络搜索,以增强问题解决能力。
- 智能规划与决策: 对于用户输入和查询,模型能生成初始推理计划,并动态决定是否需要调用外部工具。
- 上下文感知工具选择: 具备任务自适应的工具调用能力,能根据任务类型(如感知任务使用图像操作,推理任务使用数值计算)选择合适的工具。
技术原理
DeepEyesV2 采用两阶段训练法构建其智能体能力。模型在基座模型Qwen2.5-VL-7B的基础上,通过强化学习(Reinforcement Learning)进一步增强了鲁棒的工具使用行为,克服了直接强化学习在诱导工具使用行为方面的局限性。其核心机制是将程序代码执行和网络检索视为推理轨迹中可交错的工具,使模型能够在处理图像输入和用户查询时,根据需要生成推理计划并动态调用这些工具。这种统一代码执行和网络搜索的策略,使得模型能够进行可靠且复杂的推理,从而在真实世界理解、数学推理和搜索密集型任务中表现出色。
应用场景
-
复杂视觉问答: 解决需要结合视觉信息、编程计算和实时网络搜索的复杂问题。
-
多模态内容理解: 对图像和文本混合的内容进行深入分析和推理,例如电商平台上的商品描述理解与推荐。
-
智能助理与Agent: 作为能够理解视觉信息并执行外部操作的智能体,应用于各类自动化和辅助决策场景。
-
数据分析与洞察: 利用其代码执行能力对图像数据进行量化分析,提取深层洞察。
-
arXiv技术论文:https://arxiv.org/pdf/2511.05271
Kosong – 月之暗面开源的全新AI Agent开发框架
Kosong是由MoonshotAI开发的一个大型语言模型(LLM)抽象层,旨在为现代AI Agent应用提供统一、便捷的LLM交互接口。它封装了不同LLM提供商的底层差异,简化了LLM的调用、管理和集成过程,使开发者能够更高效地构建和部署复杂的AI Agent。
核心功能
- LLM抽象与统一接口: 提供标准化的API来与各种LLM(如Kimi)进行交互,屏蔽底层模型差异。
- 会话历史管理: 通过
Message对象结构化管理对话历史,支持多轮对话的上下文维护。 - 系统提示与工具集成: 允许设置
system_prompt引导模型行为,并预留了tools参数以支持外部工具调用。 - 流式响应处理: 提供
on_message_part回调机制,支持LLM响应的实时分块输出,提升用户体验。 - 可扩展的聊天提供商: 设计为可插拔架构,方便集成和切换不同的LLM服务提供商。
技术原理
Kosong的核心技术原理基于抽象层设计模式,通过定义一套统一的接口和数据结构(如Message),来封装和管理不同LLM供应商的API调用细节。其会话管理机制采用面向对象的方式,将用户输入和模型输出封装为Message实例列表,形成完整的对话历史,从而实现上下文感知能力。针对实时交互需求,Kosong集成了流式传输处理,利用StreamedMessagePart和回调函数 (on_message_part),允许LLM响应在生成过程中逐步返回,而非等待完整生成后一次性返回。此外,它通过策略模式实现了可扩展的chat_provider机制,使得集成新的LLM服务变得简单,并暗示了通过tools参数实现的函数调用或工具使用集成,以增强AI Agent的能力。
应用场景
-
智能客服与虚拟助手: 快速构建和部署支持复杂对话逻辑的智能客服系统或个人助手。
-
AI内容生成平台: 利用其抽象层能力,灵活切换不同LLM生成各类文本内容。
-
多模态AI Agent开发: 为需要与多种外部系统或工具交互的AI Agent提供LLM核心能力。
-
LLM应用原型验证: 简化新LLM模型的集成和测试,加速概念验证过程。
-
教育与研究: 作为LLM交互的标准化工具,方便教学和研究人员进行模型比较与实验。
-
Github仓库:https://github.com/MoonshotAI/kosong
KaLM-Embedding – 腾讯推出的文本嵌入模型系列
KaLM-Embedding是由腾讯团队(及哈工大团队)开发的一系列高性能文本嵌入模型。该模型系列旨在通过采用先进的训练技术和大规模、高质量、多样化且领域特定的训练数据,显著提升文本嵌入的性能。KaLM-Embedding模型以其紧凑性和通用性著称,在多语言和各种通用文本嵌入任务中表现出色,尤其在大语言模型(LLM)的检索增强生成(RAG)应用中扮演关键角色。
核心功能
- 高性能文本嵌入: 能够将文本高效地转换为低维向量表示,准确捕捉语义信息。
- 多语言支持: 具备处理和嵌入多种语言文本的能力,实现跨语言任务。
- 通用性强: 适用于广泛的通用文本嵌入任务,提供强大的语义表示基础。
- 紧凑高效: 模型设计紧凑,能够在保持卓越性能的同时,优化资源消耗和推理速度。
- 支持RAG应用: 为检索增强生成等大型语言模型应用提供高质量的语义检索能力。
技术原理
KaLM-Embedding模型的成功得益于其创新的训练范式和数据策略:
- 知识注入 (Knowledge in Large Language Models): 模型名称暗示其训练过程可能融合了大型语言模型中蕴含的丰富知识,从而增强了嵌入向量的语义表示能力和泛化性。
- 高质量与多样化数据训练: 模型利用了大量经过精心筛选、去噪且包含多领域、多语言特点的训练数据,确保了嵌入的鲁棒性和对不同文本模式的适应性。
- 先进训练技术: 采用了优化的训练策略和技术(如对比学习、自监督学习或多任务学习等),以最大化数据利用效率,提升模型在语义相似度匹配上的表现。
- 潜在的大模型基础: 提及的“Gemma3-12B”版本可能表明模型构建或微调是基于类似Gemma系列的大型语言模型,利用其强大的预训练能力。
- 模型结构优化: 通常基于Transformer编码器架构,并通过结构优化、知识蒸馏、量化等技术实现模型紧凑化,从而提高部署效率和降低计算成本。
应用场景
-
检索增强生成 (RAG): 为大型语言模型提供精确的上下文信息,提升生成内容的准确性、相关性和时效性。
-
语义搜索与信息检索: 通过匹配查询和文档的语义向量,实现更智能、更准确的搜索结果,广泛应用于搜索引擎、企业知识库等。
-
文本分类与聚类: 作为文本特征提取器,支持对文章、评论、邮件等进行高效的分类、标签识别和主题聚类。
-
问答系统: 匹配用户问题与预定义答案或文档中的相关段落,提升问答系统的智能化水平。
-
推荐系统: 基于用户行为和内容语义相似度,进行个性化内容或商品的推荐。
-
去重与相似性检测: 识别重复或高度相似的文本内容,应用于内容管理、版权保护等领域。
-
跨语言应用: 利用其多语言能力,实现跨语言搜索、文档对齐等国际化应用。
-
HuggingFace模型库:https://huggingface.co/tencent/KaLM-Embedding-Gemma3-12B-2511
-
arXiv技术论文:https://arxiv.org/pdf/2506.20923
3. AI-Compass
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:*******************************************
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力




