
AI-Compass RAG+workflow模块:检索增强生成与工作流编排技术生态构建知识密集型A
AI-Compass RAG+workflow模块:检索增强生成与工作流编排技术生态构建知识密集型AI应用
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
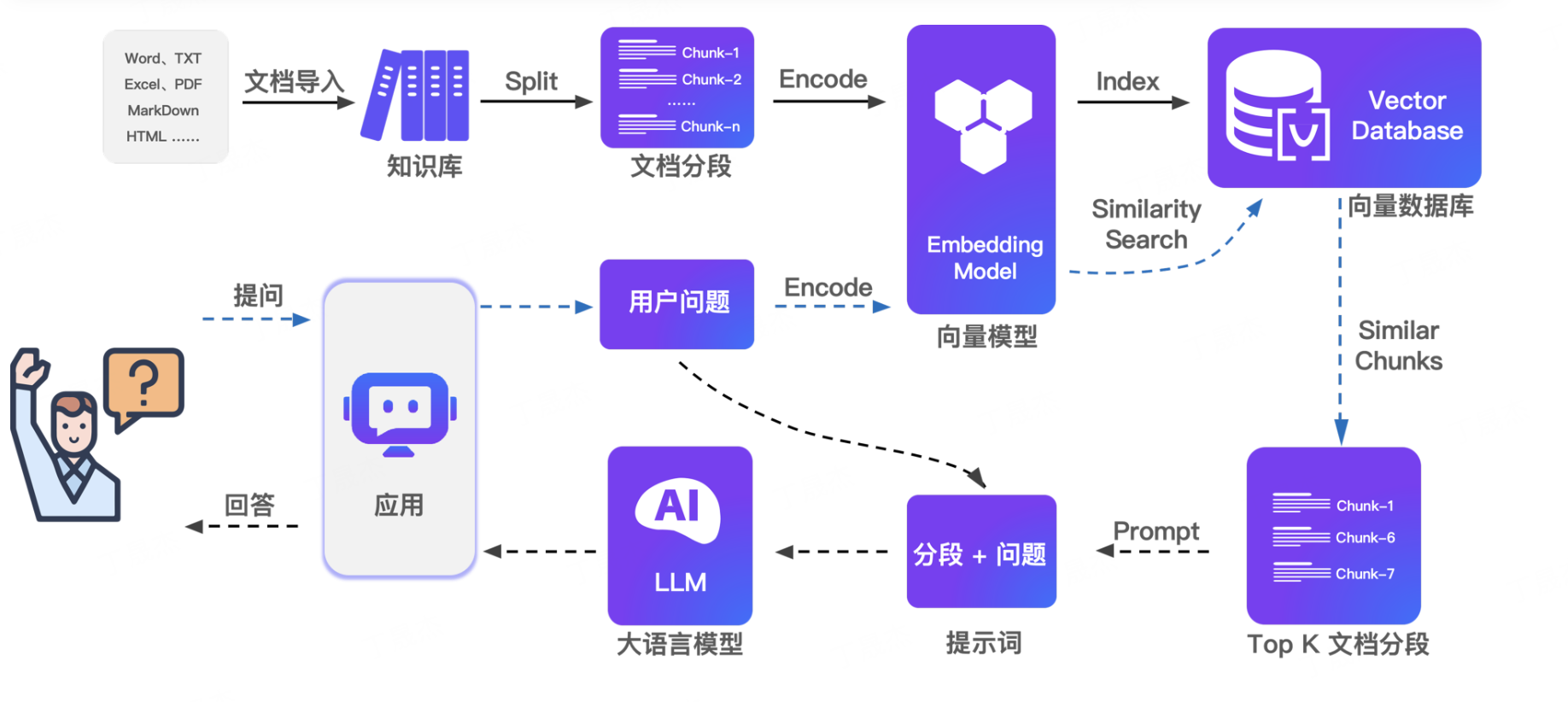
RAG+workflow模块构建了涵盖20+个核心框架的检索增强生成与工作流编排技术生态,专注于知识密集型AI应用的构建与优化。该模块系统性地整理了LangChain RAG框架、LlamaIndex数据连接器、Haystack NLP框架、Dify工作流平台、FastGPT知识库问答等主流技术栈,以及RAGFlow可视化RAG、QAnything文档问答、Quivr第二大脑等创新解决方案。技术特色涵盖了文档解析与分块、向量化存储、语义检索、上下文融合、答案生成等完整RAG流程,详细解析了混合检索、重排序算法、上下文压缩、多跳推理等高级技术。
模块深入介绍了工作流设计模式(顺序、并行、条件、循环)、节点类型定义(LLM、工具、判断、代码)、状态管理机制、错误处理策略等工作流编排核心技术,以及与企业系统(CRM、ERP、知识库)的集成方案。内容包括文档问答、智能客服、知识管理、内容生成等典型应用场景的架构设计,以及性能优化(缓存策略、并发控制、资源调度)、质量保障(答案评估、幻觉检测、事实核查)等工程化实践,帮助开发者构建高质量的知识增强型AI应用,实现企业知识的智能化管理和精准问答服务。
目录
- 0.RAG技术总图(模块化)
- 1.Anything-LLM
- 1.Chatbox
- 1.Dify.AI
- 1.Dify.AI/dify-DSL
- 1.FastGPT
- 1.FastGPT/laf快速接入三方
- 1.FastGPT/sealos云操作系统
- 1.LangBot
- 1.MaxKB
- 1.MaxKB/Halo - 强大易用的开源建站工具
- 1.Ragflow
- 1.kotaemon
- 1.lobe-chat
- 1.n8n
- 1.字节FlowGram
- 2.AstrBot-聊天机器人
- 2.AutoRAG
- 2.BISHENG毕昇
- 2.Chat-ollama
- 2.ChatALL
- 2.FlashRAG
- 2.Flowise
- 2.LangBot-即时通信机器人平台
- 2.Langchain-Chat
- 2.Langchain-Chat/langchain-chat-github-issue
- 2.Langflow
- 2.Librechat
- 2.NextChat (ChatGPT Next Web)
- 2.PandaWiki
- 2.QAnything-网易
- 2.Quivr开源云端知识库检索项目
- 2.VRAG-qwen 多模态
- 2.chat-langchain
- 2.chatwoot
- 2.comfyUI
- 2.fast-wiki
- 2.ragapp
- 2.rasa-对话系统
- 3.Chainlit
- 3.OpenChat
- 3.Verba
- 3.Zep:AI 助手的长期记忆
- 3.danswer
- 3.private-gpt
- 4.TurboRAG
- 4.dialoqbase
- 4.knowledge_gpt
- 4.rag-gpt
- 4.ten_framework
0.RAG技术总图(模块化)
该仓库围绕检索增强生成(RAG)展开,收集并分类相关论文,涵盖RAG的方法分类(基础、增强等)、应用分类(文本、代码、音频等多领域),还提及基准测试,且会持续更新以跟上领域快速发展。
1.Anything-LLM
简介
AnythingLLM 是一个一体化的人工智能应用,专为个人和团队设计,旨在将任何文档、资源或内容转化为可供大型语言模型 (LLM) 使用的上下文参考。它支持本地部署、桌面应用以及 Docker 环境,并具备完整的检索增强生成 (RAG) 和 AI Agent 能力,能够构建私有化的专属知识库,实现与文档的智能对话。
核心功能
- 私有知识库构建与管理: 能够将用户提供的文档、文本内容导入并转化为 LLM 可用的上下文,构建私有化的知识库。
- RAG (检索增强生成) 能力: 集成了 RAG 机制,使得 LLM 在生成回答时能检索并引用私有知识库中的相关信息,提高回答的准确性和可靠性。
- AI Agent 功能: 支持创建和配置 AI Agent,具备自定义技能和工具使用能力,如文档摘要、网页抓取等,以执行复杂任务。
- 多模型与向量数据库支持: 兼容多种商业及开源大型语言模型(如 OpenAI、Google LLMs、Ollama、LM Studio等)和多种向量数据库(如 Pinecone, Chroma, Qdrant, Weaviate),提供灵活的部署和集成方案。
- 本地及远程部署: 提供桌面版本、Docker 容器化部署选项,支持本地运行和远程托管,满足不同用户和团队的部署需求。
- 用户与团队协作: 支持多用户访问和团队协作功能,保障数据隐私和安全。
- 向量数据库管理: 配合 Vector Admin 工具,提供统一的图形用户界面 (GUI) 管理和操作多种向量数据库。
技术原理
AnythingLLM 的核心技术原理是基于检索增强生成 (Retrieval-Augmented Generation, RAG) 架构。
- 数据摄取与向量化: 用户上传的文档、文本等非结构化数据经过处理,通过嵌入模型 (Embedding Model) 转换为高维向量表示(即向量嵌入),并存储在支持相似性搜索的向量数据库中。
- 检索机制: 当用户提出查询时,查询内容同样被向量化。系统在向量数据库中执行相似性搜索,快速检索出与查询最相关的文档片段或信息。
- 生成增强: 检索到的相关信息(上下文)与用户原始查询一起作为输入,传递给大型语言模型 (LLM)。LLM 利用这些上下文信息来生成更准确、更具体、更符合事实的回答,避免了“幻觉”现象。
- AI Agent 框架: 引入 AI Agent 机制,Agent 可配置调用不同的“工具”或“技能”(如 RAG 工具、总结工具、网页抓取工具),实现复杂任务分解和执行,提升自动化能力。
- 模块化设计: 采用全栈应用架构,前后端分离,支持不同的 LLM 提供商和向量数据库插件化集成,增强了系统的可扩展性和可定制性。
应用场景
- 企业内部知识管理: 构建专属企业知识库,员工可以快速查询内部文档、项目资料、SOP等,提高信息检索效率和团队协作。
- 客户服务与支持: 搭建基于公司产品手册、FAQ的智能客服系统,提供精准的自动化回复,减轻客服压力。
- 研发与技术支持: 工程师和研究人员可以利用其快速检索技术文档、代码库、论文等,加速研发进程和问题解决。
- 法律与金融合规: 在法律条款、合同、财务报告等领域构建私有知识库,进行合规性审查、信息提取和风险评估。
- 教育与培训: 教师和学生可利用其整理学习资料、教材,构建个性化学习助手,实现问答和知识点梳理。
- 个人信息管理: 用户可以整理个人笔记、研究资料、邮件等,形成个人专属的智能助手,方便信息回顾和内容创作。
- Mintplex-Labs/anything-llm: The all-in-one Desktop & Docker AI application with full RAG and AI Agent capabilities.
- AnythingLLM | The all-in-one AI application for everyone
- AnythingLLM官方手册
- AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)-CSDN博客
- Mintplex-Labs/vector-admin: The universal tool suite for vector database management. Manage Pinecone, Chroma, Qdrant, Weaviate and more vector databases with ease.
1.Chatbox
简介
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,有社区版和专业版。可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用,主要功能免费,能实现与文档和图片聊天、代码生成与预览、实时联网搜索等功能,且重视用户数据隐私与安全。
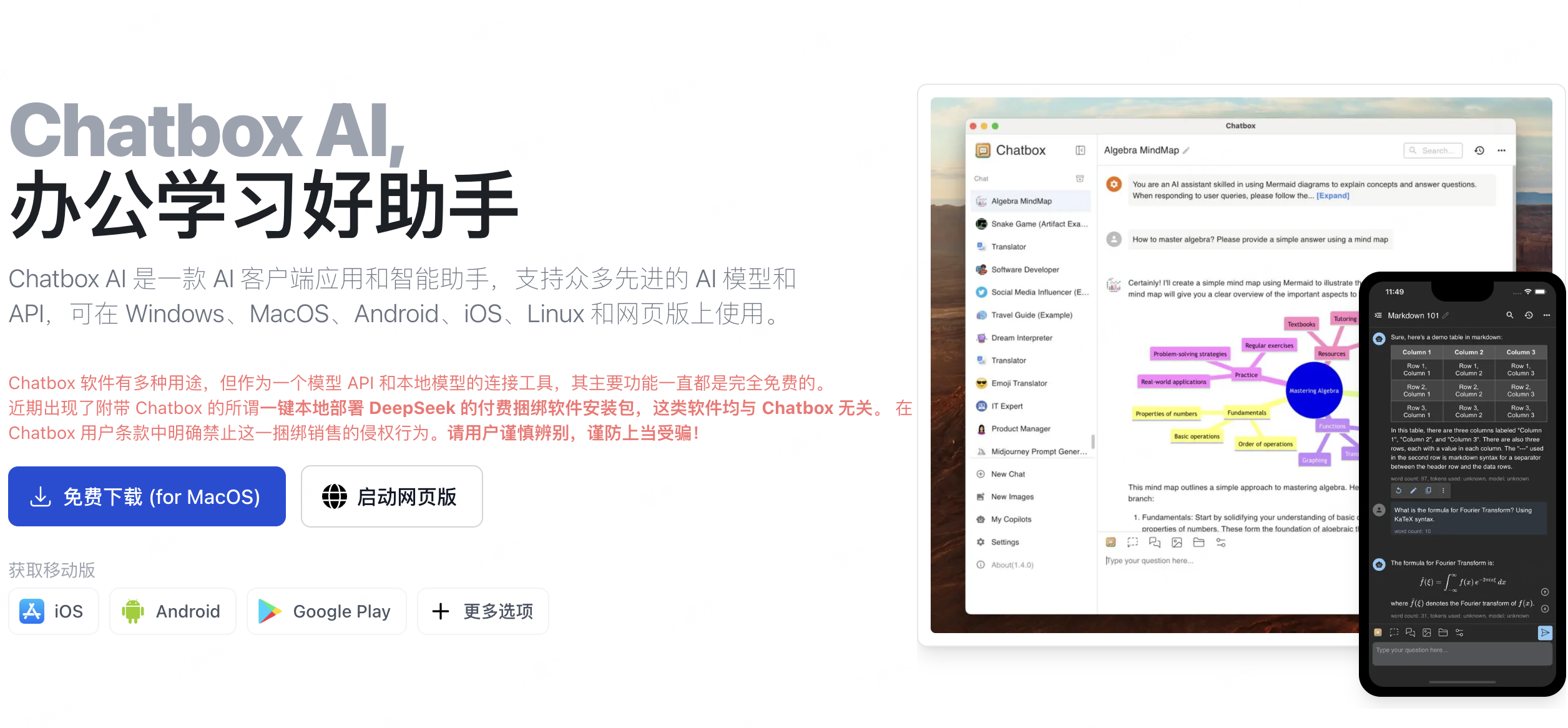
核心功能
- 多模型支持:无缝集成多种语言模型,如 OpenAI、Azure OpenAI、Claude、Google Gemini Pro 等。
- 数据处理:本地存储数据,保证隐私,具备数据备份和导出功能,可搜索消息历史。
- 文件交互:与文档、图片、代码文件聊天,理解内容并提供响应。
- 代码辅助:高效生成代码,具备预览、语法高亮、审查、重构等功能。
- 联网搜索:通过 AI 联网获取即时信息。
- 图像生成:使用 Dall - E - 3 或 Chatbox 的图像生成功能创作图片。
- 提示优化:有高级提示功能和提示库,可保存和组织提示。
- 便捷操作:支持键盘快捷键、流式回复,具备多语言支持和团队协作功能。
应用场景
- 办公学习:辅助撰写文档、分析数据、解答专业问题,提高工作和学习效率。
- 代码开发:生成代码、审查和重构代码、调试程序。
- 创意设计:生成图像、构思创意内容。
- 信息查询:实时联网搜索获取最新新闻、事实和数据。
1.Dify.AI
简介
Dify 是一个开源的 LLM 应用开发平台,旨在帮助开发者和企业高效地构建、部署和管理由大语言模型驱动的 AI 应用。它提供直观的界面,集成了 AI 工作流、RAG(检索增强生成)管道、智能代理能力、模型管理和可观测性等功能,加速了从原型到生产的整个过程。Dify 也支持插件市场,允许用户探索、分享和部署增强其应用能力的各种插件。
核心功能
- AI 工作流构建: 提供可视化界面,支持拖拽式组件,简化复杂的 AI 工作流设计与编排。
- RAG 管道集成: 内置检索增强生成能力,使 AI 应用能够结合外部知识库,提升回答的准确性和实时性。
- 智能代理能力: 支持开发和部署自主智能体,实现自动化决策和任务执行。
- 模型管理: 统一管理多种大型语言模型,方便模型的选择、切换和优化。
- 可观测性: 提供全面的监控和日志功能,帮助开发者追踪应用性能和问题排查。
- 插件与扩展: 拥有丰富的插件生态系统,支持通过 HTTP webhooks 进行外部集成,增强应用功能多样性。
- 代码执行环境: 提供轻量级、快速且安全的沙盒环境 (Dify Sandbox),支持多语言代码执行。
技术原理
Dify 的核心技术原理围绕大型语言模型的应用开发与管理展开:
- 模块化架构: 平台采用模块化设计,将AI工作流、RAG、Agent等功能封装为可插拔的组件,便于灵活组合与扩展。
- RAG 实现机制: 通过向量数据库和索引技术,将外部知识数据转化为可检索的形式,并在生成阶段结合LLM进行信息增强。
- Agentic AI 框架: 基于 LLM 的规划、工具使用和自我修正能力,构建能够自主感知、推理和执行任务的智能代理。这通常涉及行动链(Chain-of-Thought, CoT)等策略。
- 容器化与沙盒技术: Dify Sandbox 利用容器化技术(如 Docker 或类似技术)为代码执行提供隔离、安全的运行环境,确保多语言代码在无干扰、高效率下运行。
- API 驱动与微服务: 平台通过标准化的 API 接口暴露核心功能,便于开发者进行集成和二次开发;内部可能采用微服务架构,提高系统的可伸缩性和鲁棒性。
- 多模型兼容性: 设计通用的模型抽象层,使其能够适配并管理来自不同提供商的多种 LLM,实现模型即插即用。
应用场景
- 企业级 AI 应用开发: 快速构建和部署客户服务、智能助理、内容生成、数据分析等企业级 AI 解决方案。
- 智能体(Agent)开发: 创建能够自主执行复杂任务的智能代理,如自动化工作流、智能决策系统。
- 知识库问答系统: 结合企业内部文档、数据库,构建精确、实时的智能问答系统。
- AI 驱动的数据分析与报告: 利用 LLM 的理解和生成能力,对大量数据进行分析并生成可读性强的报告。
- 个性化推荐系统: 通过理解用户偏好和内容特征,生成高度个性化的推荐。
- 教育与研究: 提供一个实验和探索 LLM 应用的平台,加速创新和学习过程。
- 开发者工具链: 为 AI 开发者提供一站式、生产就绪的工具链,从原型到部署全生命周期管理。
- langgenius/dify: Dify is an open-source LLM app development platform. Dify's intuitive interface combines AI workflow, RAG pipeline, agent capabilities, model management, observability features and more, letting you quickly go from prototype to production.
- dify-sandbox: A lightweight, fast, and secure code execution environment that supports multiple programming languages
- Dify | 中文手册
- Dify.AI · The Innovation Engine for Generative AI Applications
- Milvus×Dify半小时轻松构建RAG系统 - Zilliz 向量数据库
- Dify Agent 驱动轻量级 MCPserver:联动 Zapier 实现智能搜索高效数据流转_mcp server ai搜索-CSDN博客
dify-DSL
简介
BestBlogs.dev 汇集顶级软件编程、人工智能等领域文章,利用大语言模型进行评分、摘要、翻译等,提供 RSS 订阅源和精选推送。Awesome - Dify - Workflow 则分享 Dify 工作流程,支持多任务并行等特性,还组建 VIP 群解答问题,有多种工作流文件示例及相关问题解答。
核心功能
- BestBlogs.dev:提供多领域文章精选内容,利用大语言模型进行文章、播客、推文智能分析,包括评分、摘要、翻译等,支持 RSS 订阅和定期推送。
- Awesome - Dify - Workflow:分享 Dify 工作流,支持多任务并行等特性,解答 Dify 使用相关问题,提供多种工作流文件示例供导入使用。
技术原理
- BestBlogs.dev:基于 RSS 协议爬取文章信息,通过无头浏览器获取完整内容,利用正文选择器提取正文并标准化处理。使用大语言模型进行文章初评、深度分析、多语言翻译等。播客、推文分析分别基于通义听悟、XGo.ing 和 Dify 实现。
- Awesome - Dify - Workflow:工作流采用 DSL 模式,包含基础输入、条件判断、变量聚合器、输出等内容,可方便发布为工具嵌入 ChatBot 流程。
应用场景
-
BestBlogs.dev:适用于技术开发者、产品设计师、商业人士及自我成长学习者,用于获取多领域优质文章,节省阅读时间,提升学习效率。
-
Awesome - Dify - Workflow:适合 Dify 用户进行工作流学习、开发、实践,可用于数据分析、内容翻译、知识库问答、聊天机器人开发等场景。
-
分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows.
1.FastGPT
简介
FastGPT 是一个基于大语言模型的知识平台,也是 AI Agent 构建平台,提供数据处理、RAG 检索、模型调用、可视化 AI 工作流编排等开箱即用的能力,能让用户轻松开发和部署复杂问答系统。其项目技术栈为 NextJs + TS + ChakraUI + MongoDB + PostgreSQL (PG Vector 插件)/Milvus。
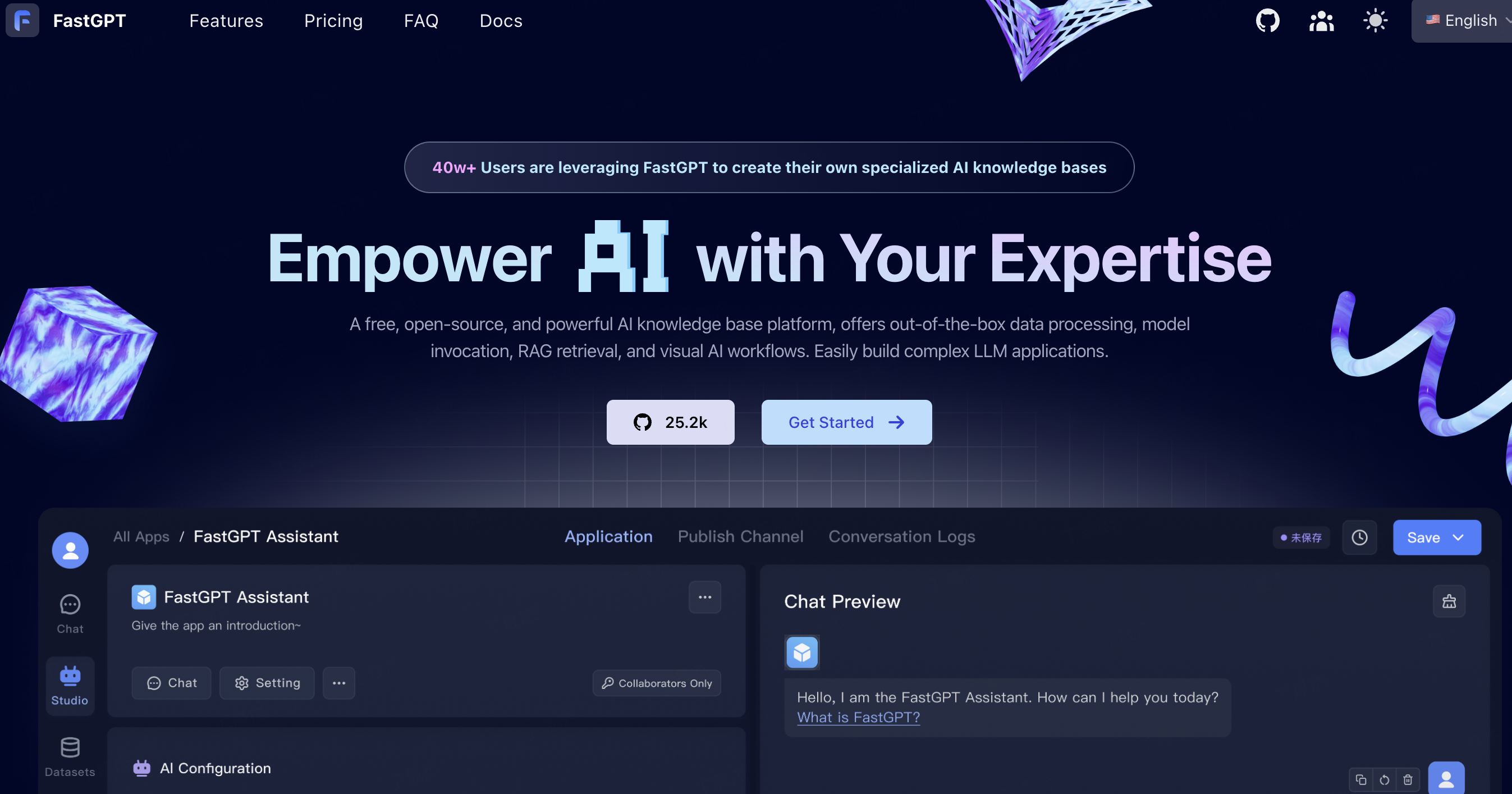
核心功能
- 数据处理:支持多种文档格式导入,自动进行文本预处理、向量化和 QA 分割。
- 模型调用:兼容多种大语言模型,只要 API 与 OpenAI API 对齐即可使用。
- 工作流编排:通过 Flow 可视化进行工作流编排,支持对话工作流、插件工作流等。
- 知识库管理:具备多库复用、混合检索、API 知识库等功能。
- 应用调试:提供知识库单点搜索测试、完整上下文呈现等调试功能。
- OpenAPI 接口:提供 completions 接口、知识库 CRUD 等接口。
- 运营能力:支持免登录分享窗口、Iframe 一键嵌入等。
技术原理
FastGPT 采用 NextJs、TS 等构建前端,结合 ChakraUI 进行界面设计,使用 MongoDB、PostgreSQL 及相关插件存储数据。通过将文档进行文本预处理、向量化,存储到知识库中,在检索时进行混合检索和重排。工作流编排通过可视化界面将各个模块组合,实现复杂应用逻辑。与模型的交互通过对齐 OpenAI API 进行调用。
应用场景
-
特定领域 AI 助手:通过导入文档或问答对训练模型,创建特定领域的聊天机器人。
-
客户服务:提高问答准确性,为客户提供更好的服务。
-
企业应用开发:作为后端服务或应用开发平台,帮助企业构建复杂的 LLM 应用。
-
自动化流程:通过工作流编排,实现数据库查询、库存检查等任务的自动化。
laf快速接入三方
简介
laf是一个开源的云开发平台,遵循Apache License 2.0开源协议。它提供云函数、云数据库、云存储、网站托管、WebSocket支持、WebIDE等开箱即用的应用资源,让开发者无需关注服务器运维,专注于业务开发。适合前端开发者、后端开发者、独立开发者和创业团队等使用,支持私有化部署。
核心功能
- 提供云函数、云数据库、云存储、网站托管、WebSocket支持等资源。
- 具备WebIDE,可让开发者像写博客一样写代码。
- 支持静态网站托管,可直接同步部署前端网页。
- 提供快速私有化部署方案。
技术原理
laf作为开源云开发平台,以Serverless架构为基础,消除冷启动时间,提升响应速度。通过提供标准化的云函数、云数据库、云存储等资源接口,让开发者无需关心底层服务器运维,实现应用资源的快速调配与使用。同时,借助开源的高度可扩展性,允许开发者根据需求定制和修改平台。
应用场景
-
前端开发者:可快速转变为全栈开发者,无门槛上手前后端开发,实现静态网站托管。
-
后端开发者:从服务器运维等琐事中解放,专注业务开发,提升效率,降低成本。
-
独立开发者和创业团队:节约成本,快速启动项目,提高迭代速度,专注产品业务验证。
sealos云操作系统
简介
Sealos 是一款以 Kubernetes 为内核的云操作系统发行版,抛弃传统云计算架构,转向以 Kubernetes 为云内核的新架构。它可让企业像使用个人电脑一样简单地使用云,具备应用管理、数据库管理等功能,具有高效经济、通用性强、灵活安全等优势,还提供社区支持与公开发展路线图。
核心功能
- 应用管理:在模板市场中轻松管理并快速发布可公网访问的分布式应用。
- 数据库管理:秒级创建高可用数据库,支持 MySQL、PostgreSQL、MongoDB 和 Redis。
- 公私一致:既是公有云也是私有云,支持传统应用无缝迁移到云环境。
技术原理
Sealos 以 Kubernetes 作为内核构建云操作系统发行版,在 Sealos 4.0 中广泛利用 Buildah 的能力,确保集群镜像与 OCI 标准兼容,通过多租户共享机制实现资源隔离与协作,利用自动伸缩功能避免资源浪费。
应用场景
-
快速部署分布式应用:如在 30 秒内轻松部署 Nginx、启动高可用数据库、运行 WordPress、Uptime Kuma 拨测系统、低代码平台、聊天应用等。
-
开发环境搭建:可一键创建开发环境,支持多种语言和框架,能通过多种 IDE 访问。
-
数据库创建与管理:可快速创建数据库并查看访问详情。
-
Docker 镜像部署:使用 Kubernetes Deployment 部署 Docker 镜像并通过 Ingress 暴露服务。
1.LangBot
简介
LangBot 是一个简单易用的大模型即时通信机器人开发平台,具有高稳定、支持扩展、多模态等特点。它支持多种即时通信平台,集成了众多大模型和 Agent,还具备丰富的功能和插件机制,可通过 Web 管理面板进行管理。
核心功能
- 大模型对话与 Agent:支持多模型,适配多种聊天场景,具备多轮对话、工具调用和多模态能力。
- 高稳定性机制:有访问控制、限速、敏感词过滤等功能,支持多流水线配置。
- 插件扩展:支持事件驱动、组件扩展等插件机制,适配特定协议,有数百个插件。
- Web 管理:可通过浏览器管理实例,无需手动编写配置文件。
技术原理
LangBot 集成了多种大模型和 Agent,通过适配不同即时通信平台的接口实现消息交互。利用插件机制实现功能扩展,采用事件驱动和组件扩展方式,适配 Anthropic MCP 协议。同时,具备原生的访问控制、限速等机制保障稳定性。
应用场景
-
客服场景:在企业微信、个人微信等平台为客户提供咨询服务。
-
群聊娱乐:在 QQ 群、Discord 等群组中提供娱乐互动、知识问答等功能。
-
信息推送:在飞书、钉钉等平台为团队成员推送重要信息。
1.MaxKB
简介
MaxKB 是飞致云旗下强大易用的企业级开源 AI 助手,它集成了检索增强生成(RAG)管道,支持强大的工作流和先进的 MCP 工具使用能力。该产品致力于解决企业 AI 落地面临的技术门槛高、部署成本高、迭代周期长等问题,广泛应用于智能客服、企业内部知识库、学术研究和教育等场景。
核心功能
- 知识库构建:支持直接上传文档或自动爬取在线文档,具备自动文本拆分、向量化功能,能有效减少大模型幻觉,提供优质智能问答体验。
- 快速集成:零编码快速嵌入第三方业务系统及常见办公应用,使现有系统快速拥有智能问答能力。
- 工作流编排:内置强大工作流引擎和函数库,支持编排 AI 工作过程,满足复杂业务场景需求。
- 多模型支持:支持多种大模型,包括私有模型和公共模型。
- 多模态交互:原生支持文本、图像、音频和视频的输入输出。
技术原理
- 前端:采用 Vue.js 构建用户界面。
- 后端:使用 Python / Django 搭建服务。
- LLM 框架:基于 LangChain 实现大模型交互。
- 数据库:运用 PostgreSQL + pgvector 存储和管理数据。
应用场景
- 智能客服:解决客服场景中服务时长受限、人力成本高、服务质量参差不齐等问题。
- 企业内部知识库:为员工提供业务知识查询和解答。
- 学术研究与教育:辅助学术资料查询和教学答疑。
- 员工业务助手:帮助员工处理日常业务流程,提升工作效率。
- 1Panel-dev/MaxKB: 🚀 基于 LLM 大语言模型的知识库问答系统。开箱即用、模型中立、灵活编排,支持快速嵌入到第三方业务系统,1Panel 官方出品。
- 官网MaxKB(2w) - 基于大语言模型的知识库问答系统
- 飞致云 - 为数字经济时代创造好软件
- MaxKB 文档手册
- FIT2CLOUD 知识库
- 技术博客 – FIT2CLOUD 飞致云
Halo - 强大易用的开源建站工具
简介
Halo 是强大易用的开源建站工具,采用 GPL-v3.0 协议开源。它具有可插拔架构、功能丰富的主题机制和富文本编辑器等特性,支持插件扩展、模板定制、附件管理和全文搜索等功能。用户可通过 Docker 或 1Panel 等方式部署,其官网为 https://www.halo.run 。
核心功能
- 可插拔架构:支持按需安装、卸载插件,集成三方平台。
- 主题机制:提供丰富主题模板,支持动态切换、实时编辑和预览。
- 富文本编辑器:功能完备,支持图片上传、视频插入等。
- 附件管理:支持多存储策略,可通过插件扩展存储位置。
- 全文搜索:内置搜索引擎,支持关键字搜索,可通过插件扩展。
技术原理
Halo 采用可插拔架构,降低功能模块间耦合度,通过提供插件开发接口实现扩展性和可维护性。其主题机制基于模板系统,允许用户自定义配置和预览。富文本编辑器提供便捷创作功能,内置全文搜索引擎支持关键字搜索。此外,通过插件机制可在运行时扩展系统功能,支持多种存储策略和外部搜索引擎扩展。
应用场景
-
企业官网:如上海奥腾、山东昂拓等企业使用 Halo 构建官网,展示业务和解决方案。
-
营销产品网站:创略科技等利用 Halo 搭建以 CDP 为核心的开源营销产品网站。
-
个人博客:用户可使用 Halo 定制个性化博客,分享文章和观点。
1.Ragflow
简介
RAGFlow是一款基于深度文档理解构建的开源RAG(Retrieval-Augmented Generation)引擎,为企业和个人提供精简的RAG工作流程。结合大语言模型,它能针对复杂格式数据提供可靠问答及有理有据的引用。近期有支持跨语言查询、新增代码执行器组件等更新。
核心功能
- 基于深度文档理解,从复杂格式非结构化数据中提取知识,可在无限上下文场景下搜索。
- 提供基于模板的文本切片,智能且可控可解释,有多种模板可选。
- 文本切片可视化,支持手动调整,答案提供关键引用并可追根溯源,降低幻觉。
- 兼容多种异构数据源,如文档、表格、图片等。
- 提供自动化RAG工作流,支持大语言模型和向量模型配置,基于多路召回、融合重排序,有易用API。
技术原理
RAGFlow结合深度文档理解技术,对复杂格式数据进行处理。在检索阶段运用多路召回和融合重排序技术筛选相关信息,再结合大语言模型进行答案生成。系统依赖如Elasticsearch或Infinity等数据库存储文本和向量数据,通过合理配置系统环境变量和服务参数确保系统正常运行。
应用场景
- 企业知识问答:基于企业内部文档、数据等构建知识基地,为员工提供准确的问答服务。
- 智能客服:结合企业业务知识,为客户提供专业、有理有据的解答。
- 数据分析:从大量复杂数据中提取有价值信息,辅助决策。
- 代码执行与调试:利用代码执行器组件,对Python/JS代码进行执行和调试。
- ragflow/README_zh.md at main · infiniflow/ragflow
- infiniflow/ragflow: RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding.
- Quick start | RAGFlow
- Blog | RAGFlow
1.kotaemon
简介
Kotaemon是一个开源的、简洁且可定制的基于检索增强生成(RAG)的工具,用于与文档进行对话。它兼顾了终端用户和开发者的需求,终端用户可使用其进行文档问答,开发者则能借助它构建自己的RAG管道。
核心功能
- 提供干净简约的用户界面,支持基于RAG的问答。
- 兼容多种大语言模型(LLM),包括API提供商和本地模型。
- 易于安装,提供简单脚本快速启动。
- 支持构建自定义RAG文档问答管道。
- 可托管自己的文档问答(RAG)网页界面,支持多用户登录、文件管理和协作分享。
- 支持多模态问答,可处理包含图表和表格的文档。
- 提供高级引用和文档预览功能,确保答案正确性。
- 支持复杂推理方法,如问题分解和基于代理的推理。
- 可在界面上配置检索和生成过程的重要设置。
- 具有可扩展性,支持多种文档索引和检索策略。
技术原理
Kotaemon基于检索增强生成(RAG)技术,结合了全文检索和向量检索的混合检索器,并进行重新排序以确保最佳检索质量。使用Gradio构建用户界面,支持多种大语言模型API和本地模型。同时,它还支持多种推理管道,如简单问答管道、问题分解管道、基于ReAct和ReWOO的代理管道等。
应用场景
- 终端用户进行文档的问答和知识查询。
- 开发者构建自定义的RAG文档问答应用。
- 企业内部进行文档管理和知识共享。
- 科研人员处理包含多模态信息的科研文档。
1.lobe-chat
简介
Lobe Chat 是一款开源的、拥有现代设计的 ChatGPT/大语言模型 UI 框架,支持语音合成、多模态和可扩展(函数调用)插件系统。用户能一键免费部署私人的 OpenAI ChatGPT、Claude、Gemini 等聊天应用,适用于超级个体用户及开发者。
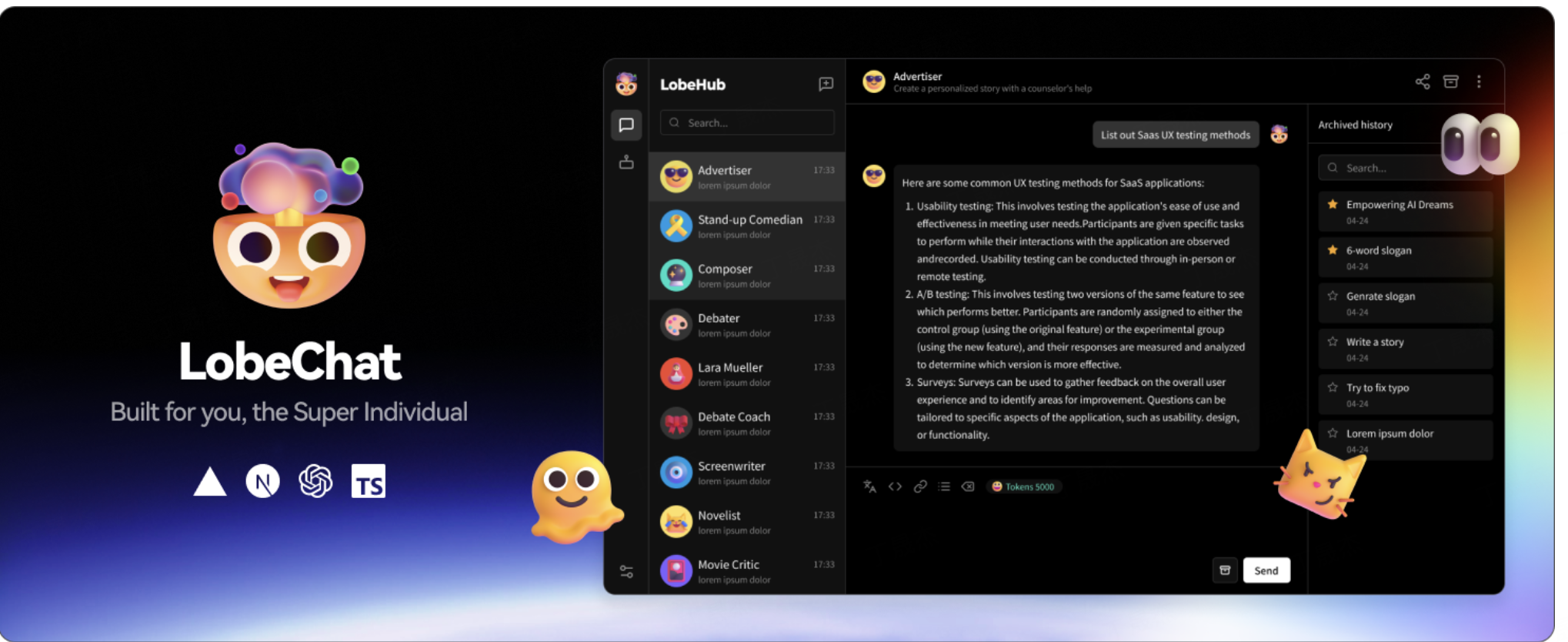
核心功能
- 对话交互:支持思维链、分支对话,提供自然灵活的聊天体验。
- 内容处理:支持文件上传、知识库管理,可利用文件和知识库进行对话。
- 多模型支持:支持超 40 种模型服务提供商,还支持本地大语言模型。
- 多模态能力:具备模型视觉识别、TTS 与 STT 语音对话、文本生成图像功能。
- 插件与市场:拥有 42 个插件,可获取实时信息;Agent 市场有 505 个代理,支持国际化。
- 其他特性:支持本地/远程数据库、多用户管理,采用 PWA 技术,适配移动设备,支持自定义主题。
技术原理
- 数据存储:本地数据库使用 CRDT 技术实现多设备同步;服务器端支持 PostgreSQL 数据库。
- 用户管理:集成 next-auth 和 Clerk 两种身份验证和管理库,满足不同安全和管理需求。
- 前端体验:采用 Progressive Web Application (PWA) 技术,优化多设备体验,使网页应用接近原生应用。
应用场景
- 学习研究:通过思维链可视化理解 AI 推理过程,利用知识库和多模型进行学习探索。
- 日常交流:语音对话、分支对话让交流更自然,自定义主题提升个性化体验。
- 内容创作:利用文本生成图像、插件系统等功能进行创意内容创作。
- 企业办公:支持多用户管理、本地/远程数据库,满足企业数据管理和协作需求。
- LobeHub - LobeChat:个人 LLM 效能工具,超越 ChatGPT / OLLaMA 使用体验
- lobe-chat/README.zh-CN.md at main · lobehub/lobe-chat
- lobehub/lobe-chat: 🤯 Lobe Chat - an open-source, modern-design LLMs/AI chat framework. Supports Multi AI Providers( OpenAI / Claude 3 / Gemini / Ollama / Bedrock / Azure / Mistral / Perplexity ), Multi-Modals (Vision/TTS) and plugin system. One-click FREE deployment of your private ChatGPT chat application.
1.n8n
简介
n8n 是一个工作流自动化平台,为技术团队提供代码灵活性与无代码速度。它拥有 400 多个集成、原生 AI 能力,采用公平代码许可,让用户构建强大自动化的同时,完全掌控数据和部署。
核心功能
-
按需编写代码:可编写 JavaScript/Python,添加 npm 包,或使用可视化界面。
-
原生 AI 平台:基于 LangChain 利用自有数据和模型构建 AI 代理工作流。
-
完全可控:可依据公平代码许可进行自托管,也可使用其云服务。
-
企业适用:具备高级权限、单点登录(SSO)和隔离部署功能。
-
社区活跃:拥有 400 多个集成和 900 多个即用型模板。
1.字节FlowGram
简介
FlowGram.AI是一个基于节点的流程构建引擎,可帮助开发者以固定布局或自由连接布局模式快速创建工作流,提供了一套交互最佳实践,适用于具有清晰输入输出的可视化工作流,同时也聚焦于用AI能力赋能工作流。
核心功能
- 支持以固定布局或自由连接布局模式创建工作流。
- 提供交互最佳实践。
- 有应用创建器、固定布局编辑器和自由布局编辑器等工具包。
- 支持复合节点如分支和循环。
应用场景
适用于具有清晰输入输出的可视化工作流场景,可用于快速创建各类工作流程。
- FlowGram.AI
- bytedance/flowgram.ai: FlowGram is a node-based flow building engine that helps developers quickly create workflows in either fixed layout or free connection layout modes
2.AstrBot-聊天机器人
简介
AstrBot 是一个松耦合、异步、支持多消息平台部署、具有易用插件系统和完善大语言模型接入功能的聊天机器人及开发框架。自带知识库能力,支持接入 MCP 服务器,基于前沿科研成果设计的相关模型将在 v3.6.0 版本提升对话体验。
核心功能
- 大语言模型对话:支持多种大模型,具备多轮对话、人格情境、多模态能力。
- 多消息平台接入:支持多个主流消息平台,具备速率限制等管理功能。
- Agent 能力:原生支持部分 Agent 能力,可对接 Dify 平台。
- 插件扩展:有深度优化的插件机制,便于开发扩展。
- 可视化管理面板:支持可视化操作,集成 WebChat。
- 高稳定性、高模块化:基于事件总线和流水线架构,低耦合。
技术原理
基于事件总线和流水线的架构设计,高度模块化、低耦合。通过接入不同大语言模型的 API 或本地部署模型加载器实现大模型对话功能;利用优化的插件机制实现功能扩展;借助可视化管理面板实现便捷配置管理。
应用场景
- 社交场景:在多个社交平台上实现智能聊天、情感陪伴。
- 办公场景:用于企业内部沟通、任务管理等。
- 开发场景:为开发者提供大模型接入和插件开发框架。
- 客户服务:在各大消息平台上为客户提供智能客服服务。
2.AutoRAG
简介
AutoRAG 是一款用于为用户数据自动寻找最优检索增强生成(RAG)管道的工具。它支持对多种 RAG 模块组合进行简单评估,用户可借助自身评估数据自动评估不同 RAG 模块,从而找出最适合自身用例的 RAG 管道。此外,还有基于网页的 AutoRAG GUI(测试版),操作更为便捷。
核心功能
- RAG 管道优化:自动评估多种 RAG 模块组合,找到适合用户数据的最优 RAG 管道。
- 数据创建:支持数据解析、分块、问答创建等操作,生成 RAG 优化所需的问答数据集和语料库数据集。
- 多方式部署:可将优化后的 RAG 管道以代码、API 服务器、网页界面等形式部署。
技术原理
AutoRAG 通过配置 YAML 文件设置 RAG 优化参数,利用多种指标(如检索指标、生成指标等)对不同节点和模块进行评估。在优化过程中,对检索、提示制作、生成等节点的不同模块组合进行测试,依据指标找出最优组合。
应用场景
-
企业知识问答系统:优化 RAG 管道,提高知识问答的准确性和效率。
-
智能客服:为客服系统提供更精准的回答,提升用户服务体验。
-
研究机构:辅助研究人员进行 RAG 相关的实验和研究。
-
Marker-Inc-Korea/AutoRAG:AutoRAG:使用 AutoML 风格自动化进行检索增强生成 (RAG) 评估和优化的开源框架
2.BISHENG毕昇
简介
BISHENG是一个面向企业场景的开源大语言模型(LLM)应用运维平台,已被众多行业领先组织和世界500强公司使用。其名称源于活字印刷术发明者毕昇,寓意为智能应用的广泛实施提供有力支持。
核心功能
- 独特工作流:独立综合的应用编排框架,支持人工干预,功能强大、操作直观,可处理复杂场景。
- 企业级特性:涵盖安全审查、用户管理、流量控制、漏洞扫描等,保障应用实施。
- 高精度文档解析:基于5年积累的大量高质量数据训练,可免费私有部署。
- 社区分享:提供应用案例和最佳实践的开放仓库。
技术原理
- 采用独立且综合的应用编排框架,实现各类任务在单一框架内执行。
- 训练高精度文档解析模型,包含印刷文本、手写文本、表格、布局分析、印章等多种识别模型。
应用场景
适用于文档审查、固定格式报告生成、多智能体协作、政策更新对比、客服支持、会议纪要生成、简历筛选等企业应用场景。
2.Chat-ollama
简介
Ollama是流行的大模型本地化工具,支持多种开源大模型。ChatOllama是基于大语言模型的开源聊天机器人,支持多种语言模型,具备多种聊天类型和管理功能,还对知识库问答体验进行了升级。
核心功能
- ChatOllama:支持多类型语言模型,提供自由聊天和基于知识库的聊天,具备模型管理、知识库管理、商业大语言模型API密钥管理等功能,还可展示回答的关联文档信息。
- Ollama:实现大模型本地化运行。
技术原理
- ChatOllama:使用向量数据库(如Chroma、Milvus)存储数据,借助Prisma进行数据库表创建和迁移,支持Ollama管理的嵌入模型或第三方服务提供商(如OpenAI)的嵌入模型。
- Ollama:暂未明确其具体技术原理,但可支持开源大模型在本地运行。
应用场景
-
ChatOllama:智能客服、知识问答、信息检索、对话交互等场景。
-
Ollama:大模型本地化测试、开发、应用等场景。
2.ChatALL
简介
ChatALL(齐叨)是一款可让用户同时与多个AI聊天机器人进行对话的客户端工具,支持ChatGPT、Bing Chat、Bard等众多AI,能帮助用户发现最佳答案,适用于大语言模型的专家、研究人员和开发者等。
核心功能
- 多模型并发对话:可同时向多个AI机器人发送提问,直观对比不同模型的回答。
- 快速提问模式:无需等待上一轮回复完成即可发送下一个提问。
- 历史记录管理:本地保存聊天记录,保护隐私,可高亮喜欢的回复、删除不满意的回复。
- 灵活配置:可随时启用或禁用机器人,切换视图模式,支持多语言、多系统。
- 自动更新:自动更新到最新版本。
技术原理
通过反向工程实现与支持网页访问的AI机器人建立连接,利用API与支持API访问的机器人通信。收集用户的匿名使用数据,如使用的AI机器人、提问时长等,以改进产品。
应用场景
-
专家用户:从多个大语言模型中寻找最佳答案或创意。
-
研究人员:直观对比不同大语言模型在不同领域的优缺点。
-
开发者:快速调试提示词,找到性能最佳的基础模型。
2.FlashRAG
简介
FlashRAG是一个用于检索增强生成(RAG)研究的Python工具包,包含36个预处理的基准RAG数据集和17种先进的RAG算法,支持多种RAG流程的复现与开发,还提供易于使用的UI。
核心功能
- 框架丰富可定制,涵盖RAG场景的关键组件,支持灵活组装复杂流程。
- 提供36个预处理的基准数据集,用于测试和验证RAG模型性能。
- 预实现17种先进RAG算法,便于在不同设置下复现结果。
- 简化预处理阶段,提供多种脚本,如语料处理、索引构建等。
- 借助vLLM、FastChat等工具优化执行效率。
- 拥有易于使用的UI,可快速配置和体验RAG基线并进行评估。
技术原理
- 利用vLLM、FastChat加速大语言模型推理,Faiss进行向量索引管理。
- 对于密集检索方法,使用faiss构建索引;稀疏检索方法(BM25),使用Pyserini或bm25s构建Lucene倒排索引。
- 支持多种RAG推理路径,如顺序、条件、分支、循环等,并实现了相应的常见管道。
应用场景
-
RAG学术研究,如复现现有SOTA工作、开发自定义RAG流程和组件。
-
问答系统、多跳问答、长文本问答、开放域摘要、事实验证等自然语言处理任务。
2.Flowise
简介
Flowise是一个开源的生成式AI开发平台,用于构建AI代理和大语言模型(LLM)工作流。它提供了可视化构建器、跟踪与分析、评估、人工干预、API、CLI、SDK、嵌入式聊天机器人等功能。有三种主要的可视化构建器:Assistant、Chatflow和Agentflow。
核心功能
- 可视化构建:提供三种可视化构建器,可创建聊天助手、单智能体系统、多智能体系统和复杂工作流编排。
- 能力全面:具备编排、数据摄取与集成、监控、部署、数据处理、记忆与规划、MCP集成、安全控制等能力。
- 多方式访问:支持API、SDK、CLI访问,有可定制的嵌入式聊天小部件和组件。
技术原理
- 编排:采用可视化编辑器,支持开源和专有模型,运用表达式、自定义代码和分支/循环/路由逻辑。
- 数据处理:通过数据转换、过滤、聚合、自定义代码和RAG索引管道进行数据处理。
- 记忆规划:使用各种内存优化技术和集成方法。
应用场景
-
AI开发:帮助开发者构建AI代理和LLM工作流。
-
聊天机器人创建:可用于创建单智能体系统、聊天机器人和简单的LLM流程。
-
复杂系统构建:适用于创建多智能体系统和复杂的工作流编排。
-
FlowiseAI/Flowise: Drag & drop UI to build your customized LLM flow
2.LangBot-即时通信机器人平台
简介
LangBot 是大模型时代的即时通信机器人平台,具有多模型、多平台适配及丰富生态的特点。它支持 OpenAI、DeepSeek、Claude 等主流大模型,适配 QQ、微信等多种消息平台,还集成了 Dify、阿里云百炼等 LLMOps 平台,提供 WebUI 方便用户快速部署和使用。
核心功能
- 支持多模型与多平台,可适配多种消息平台和主流大模型。
- 拥有丰富插件生态,涵盖聊天、漫画下载、联网、语音转换等功能。
- 提供 WebUI,方便用户快速部署和使用。
- 可通过流水线进行更多功能配置。
技术原理
LangBot 作为大语言模型原生的即时通信机器人平台,在技术架构上整合了多种大语言模型的能力,通过与不同模型供应商的接口对接,实现多模型支持。在多平台适配方面,利用各消息平台的开放 API 进行通信交互。其插件系统基于模块化设计,允许开发者开发和集成各种功能插件。同时,借助 LLMOps 平台实现模型的管理和优化。
应用场景
-
社交聊天:创建真实感聊天机器人,提供真实的聊天体验。
-
信息获取:利用联网插件获取网络信息,实现信息查询。
-
漫画处理:支持漫画下载、转 PDF 等操作。
-
语音交互:将输出内容转化为音频,实现语音聊天。
2.Langchain-Chat
简介
Langchain-Chatchat(原 Langchain-ChatGLM)是基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现的开源、可离线部署的 RAG 与 Agent 应用项目。旨在建立对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案,支持主流开源 LLM、Embedding 模型与向量数据库,可全部使用开源模型离线私有部署。
核心功能
- 模型接入:支持 Xinference、Ollama 等框架接入 GLM - 4 - Chat、Qwen2 - Instruct 等模型,兼容 OpenAI GPT API。
- 多种对话:支持 LLM 对话、知识库对话、搜索引擎对话、文件对话、数据库对话、多模态图片对话、ARXIV 文献对话、Wolfram 对话、文生图等。
- Agent 功能:可根据模型 Agent 能力不同,选择不同操作方式进行工具调用。
技术原理
项目实现过程为加载文件、读取文本、文本分割、文本向量化、问句向量化,在文本向量中匹配出与问句向量最相似的 top k 个,将匹配出的文本作为上下文和问题一起添加到 prompt 中,提交给 LLM 生成回答。依托 langchain 框架,通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
应用场景
-
知识库问答:利用本地知识库进行问答。
-
智能客服:结合多模态对话等功能,为用户提供服务。
-
文献查询:实现 ARXIV 文献对话等。
-
数据处理:进行数据库对话等操作。
langchain-chat-github-issue
- 如何实现混合检索 · Issue #3994 · chatchat-space/Langchain-Chatchat
- 知识库问答Prompt指令不生效 · Issue #3877 · chatchat-space/Langchain-Chatchat
- 如何提高知识库问答的准确性 · Issue #3882 · chatchat-space/Langchain-Chatchat
- 知识库没有多轮对话能力 · Issue #3883 · chatchat-space/Langchain-Chatchat
- 怎么通过url的方式调用知识库问答 · Issue #4070 · chatchat-space/Langchain-Chatchat
- 如何分批进行数万个文件知识库初始化? · Issue #4052 · chatchat-space/Langchain-Chatchat
2.Langflow
简介
Langflow 是用于构建和部署 AI 驱动的智能体和工作流的强大工具,具备可视化构建界面,支持主流大语言模型、向量数据库和各类 AI 工具,可将工作流集成到任意框架或堆栈构建的应用中。
核心功能
- 提供可视化构建界面,快速启动和迭代工作流。
- 支持源码访问,可使用 Python 自定义组件。
- 拥有交互式 playground,可立即测试和优化工作流。
- 支持多智能体编排,具备对话管理和检索功能。
- 可作为 API 部署或导出为 JSON 用于 Python 应用。
- 可作为 MCP 服务器部署,将工作流转变为 MCP 客户端工具。
- 支持与 LangSmith、LangFuse 等集成以实现可观测性。
技术原理
Langflow 基于 Python 开发,结合可视化构建界面,通过拖拽操作连接提示、语言模型、数据源等不同组件,构建复杂 AI 工作流。内置 API 和 MCP 服务器,可将工作流转化为工具进行集成,支持多种大语言模型和向量数据库,实现多智能体编排和对话管理。
应用场景
-
构建智能聊天机器人。
-
搭建文档分析系统。
-
生成引人入胜的内容。
-
编排多智能体应用。
2.Librechat
简介
LibreChat是一个增强版的ChatGPT克隆项目,支持多种AI模型,如DeepSeek、Anthropic、OpenAI等,具备AI模型切换、消息搜索、代码解释器等功能,开源可自托管,适合多用户使用。
核心功能
- 模型选择:支持Anthropic、AWS、OpenAI等多种AI模型及自定义端点。
- 代码解释:支持多语言代码安全沙盒执行及文件处理。
- 智能代理:可构建无代码自定义助手,集成多种工具。
- 网络搜索:搜索互联网信息增强AI上下文。
- 生成式UI:可直接在聊天中创建代码工件。
- 图像编辑:支持多种图像生成和编辑方式。
- 预设管理:创建、保存和分享自定义预设。
- 多模态交互:支持图像和文件分析、多语言UI、语音交互等。
- 搜索导出:支持消息搜索和对话导入导出。
- 多用户安全访问:支持多用户安全认证、内置审核和令牌消费工具。
技术原理
该项目整合多种AI模型和服务,利用模型上下文协议(MCP)支持工具集成,结合搜索提供商、内容抓取器和结果重排器实现网络搜索,通过沙盒技术保障代码执行安全,使用OAuth2、LDAP等实现多用户安全认证。
应用场景
-
开发场景:代码编写、调试和解释,模型选择和切换。
-
创意设计:图像生成和编辑,创建代码工件。
-
日常办公:信息搜索、多语言交流、对话管理。
-
教育学习:知识问答、文件分析、辅助学习。
2.NextChat (ChatGPT Next Web)
简介
ChatGPT-Next-Web 是一个开源项目,旨在为 ChatGPT 和 Gemini 等大型语言模型提供一个美观、快速且跨平台的图形用户界面(UI)。它支持用户一键部署自己的私人 AI 助理应用,并可在 Web、PWA、Linux、Windows、macOS、iOS 和 Android 等多个平台上运行。
核心功能
- 多模型支持: 集成对 OpenAI 的 ChatGPT (GPT-3, GPT-4) 和 Google 的 Gemini Pro 等多种大型语言模型的支持。
- 跨平台兼容性: 提供网页端、渐进式网页应用 (PWA) 以及桌面和移动端(通过 Tauri 或其他技术)的统一体验。
- 一键部署: 简化部署流程,支持通过 Vercel 等平台快速免费搭建个人应用。
- 用户界面优化: 提供简洁、直观、轻量级的聊天界面,提升用户交互体验。
- 高级功能: 包括系统提示固定、自定义用户提示管理、聊天内容分享(如分享为图片、ShareGPT)、以及与RWKV-Runner、LocalAI等模型的自部署兼容性。
- 多 API 支持: 除了OpenAI,还支持Google Gemini Pro、Anthropic Claude、百度、字节跳动、阿里云、科大讯飞、ChatGLM、DeepSeek等多种API。
技术原理
该项目主要基于 Web 技术构建用户界面,通过集成各类大语言模型的 API Key 来实现与模型的通信。其跨平台特性可能得益于现代 Web 技术(如 React、Next.js)和桌面应用框架(如 Tauri)的结合,从而将 Web 应用打包成原生桌面或移动应用。部署方面,利用如 Vercel 等平台进行无服务器部署,实现应用的快速上线与托管。核心在于前端界面的构建和后端对多模型 API 的统一管理与调用。
应用场景
- 个人AI助理: 快速搭建和部署个人专属的 ChatGPT/Gemini 聊天界面,作为日常工作和学习的智能助手。
- 开发者工具: 为开发者提供一个方便调试和测试不同大语言模型 API 的统一前端界面。
- 团队协作: 团队内部可以部署统一的 AI 聊天平台,便于成员高效使用 AI 能力。
- 跨设备使用: 用户可以在不同操作系统(Windows, macOS, Linux)和移动设备(iOS, Android)上无缝访问和使用自己的 AI 助理。
- ChatGPTNextWeb/ChatGPT-Next-Web: A cross-platform ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS). 一键拥有你自己的跨平台 ChatGPT/Gemini 应用。
- NextChat
2.PandaWiki
简介
PandaWiki 是一款由 AI 大模型驱动的开源知识库搭建系统,可帮助用户快速构建智能化的产品文档、技术文档、FAQ、博客系统。它借助大模型提供 AI 创作、AI 问答、AI 搜索等能力,还具备强大的富文本编辑、与第三方应用集成、从第三方来源导入内容等功能。
核心功能
- AI 驱动功能:提供 AI 辅助创作、问答、搜索。
- 富文本编辑:兼容 Markdown 和 HTML,支持多种格式导出。
- 第三方集成:可做成网页挂件、聊天机器人,支持与第三方应用集成。
- 内容导入:支持多种方式从第三方来源导入内容。
- 外观定制:提供丰富的外观定制功能。
- 多模型接入:支持接入百智云官方、本地及其他第三方大模型。
技术原理
PandaWiki 基于 AI 大模型驱动,内置强大的 RAG(检索增强生成)能力。它深度封装复杂技术,将大模型的智能处理能力与知识库的管理功能相结合,通过对导入文档的处理和分析,为不同的知识库分别创建 “Wiki 网站”,以实现 AI 创作、问答和搜索等功能。
应用场景
-
智能客服:为客户提供快速准确的问题解答。
-
教育培训:搭建教学资料、常见问题知识库。
-
法律咨询:整合法律条文、案例等知识。
-
医疗咨询:提供医疗知识和常见问题解答。
2.QAnything-网易
简介
QAnything是由网易有道开发的本地知识库问答系统,支持任意格式文件或数据库,可断网安装使用。具有数据安全、跨语种问答、支持海量数据等特点,采用两阶段向量排序解决大规模数据检索退化问题,其开源版本基于通义千问微调,增强了问答能力。
核心功能
- 多格式支持:支持PDF、Word、PPT、Markdown等多种格式文件及数据库。
- 跨语种问答:中英文问答随意切换,不受文件语种限制。
- 海量数据问答:两阶段向量排序,解决大规模数据检索退化问题。
- 高性能部署:可直接部署企业应用,支持多并发、多卡推理。
- 易用性强:一键安装部署,无需繁琐配置。
- 多知识库选择:支持选择多知识库进行问答。
技术原理
- 两阶段检索:一阶段采用embedding检索,二阶段使用rerank重排,解决数据量增大时的检索退化问题。
- BCEmbedding组件:具备双语和跨语种能力,消除中英语言差异,实现强大的语义表征和RAG评测表现。
- 大模型微调:开源版本基于通义千问,在大量专业问答数据集上微调,加强问答能力。
应用场景
- 学术研究:对多篇英文论文进行跨语种问答和信息抽取。
- 企业知识管理:处理各种格式文件,实现企业内部知识库问答。
- 网页信息查询:针对网页链接内容进行问答。
- API接入开发:支持开发者接入API进行二次开发。
- QAnything/README_zh.md at master · netease-youdao/QAnything
- netease-youdao/QAnything: Question and Answer based on Anything.
- QAnything
- 有道QAnything · 模型库详细
- 有道QAnything · 模型库
- netease-youdao/QAnything: Question and Answer based on Anything.
2.Quivr开源云端知识库检索项目
简介
Quivr是开源的AI知识库解决方案,可将本地文件向量化后存储到云端,支持文本、图像、视频、代码片段等内容上传,用户能通过LLM实现信息检索和问答。它兼容多种文件格式,采用先进人工智能技术,具有安全可靠、快速高效等特点,且免费使用。
核心功能
- 文件处理:支持上传文本、Markdown、PDF、音视频等多种格式文件。
- 信息检索与问答:借助GPT - 3/4、Claude等模型,实现基于上传文件内容的信息检索和问答。
- 数据管理:提供数据存储、重复文件校验、文件拆分与向量化等功能。
技术原理
- 文件加载:使用LangChainAI实现,上传文件时计算元数据,如SHA1值。
- 文件存储:将文档拆分后存储到Supabase向量数据库,用OpenAI Embeddings计算向量值。
- 信息查询:选择模型创建ConversationalRetrievalChain,发送问题进行查询。
应用场景
-
个人知识管理:用户可将学习、工作资料上传,随时查询相关信息。
-
企业知识共享:企业可将各类文档存储在Quivr,方便员工检索知识。
-
项目资料管理:项目团队可上传项目相关文件,便于成员获取信息。
2.VRAG-qwen 多模态
简介
VRAG - RL是阿里巴巴提出的用于视觉丰富信息复杂推理的强化学习框架。它改进了现有视觉检索增强生成(RAG)方法在处理视觉信息时推理能力激活不足、检索效率低和多轮推理不稳定等问题,通过引入视觉感知动作空间、细粒度检索奖励等提升了视觉语言模型(VLMs)在视觉信息检索和推理方面的性能。
核心功能
- 视觉感知:定义视觉感知动作空间,使VLMs能从粗到细获取图像信息,聚焦高信息密度区域,增强视觉感知能力。
- 高效检索:设计包含检索效率奖励、模式一致性奖励和基于模型的结果奖励的细粒度奖励函数,引导模型高效检索相关信息。
- 多轮推理:运用强化学习实现多轮推理,使模型在与搜索引擎交互时保持稳定和一致,灵活调整策略完成复杂推理任务。
技术原理
- 视觉感知动作空间:考虑视觉信息特点定义动作空间,通过选择和重新编码感兴趣区域,在令牌级别实现区域选择和缩放,提升视觉感知分辨率。
- 奖励函数设计:奖励函数由检索效率奖励(基于改进的归一化折损累积增益)、模式一致性奖励(基于规则提取动作)和基于模型的结果奖励(使用评估模型评估答案正确性)加权组合而成。
- 强化学习训练:采用Group Relative Policy Optimization(GRPO)算法优化模型,通过与外部环境交互采样轨迹,最大化目标函数提升模型性能。
应用场景
- 文档视觉问答:如SlideVQA数据集,处理幻灯片相关的复杂推理问题,包括单跳、多跳和数值推理等。
- 视觉文档检索推理:像ViDoSeek数据集,针对大规模文档集合进行检索、推理和回答任务。
- 长上下文多模态文档理解:如MMLongBench数据集,评估VLMs对包含文本、图像、图表等的长上下文文档的理解能力。
- Alibaba-NLP/VRAG: Repo for "VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning"
- VRAG-RL - a autumncc Collection
- VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
2.chat-langchain
简介
链接涉及Chat LangChain相关内容,包含其GitHub项目页面和在线聊天页面,从聊天页面问题可知与LangChain使用、技术实现等相关。
核心功能
- 提供关于LangChain使用的交流与问答。
- 帮助解决LangChain在加载内容、定义状态模式、本地运行模型、实现RAG技术等方面的问题。
应用场景
-
开发者在使用LangChain进行开发时遇到问题寻求解决方案。
-
学习者了解LangChain的各项技术及应用。
2.chatwoot
简介
Chatwoot是一款现代、开源且支持自托管的客户支持平台,可替代Intercom、Zendesk等工具。它能集中管理多渠道客户对话,提供AI代理、帮助中心门户等功能,还有丰富的协作、数据管理、集成、报告等特性。
核心功能
- AI代理:借助Captain自动回复、处理常见问题,减轻客服工作量。
- 全渠道支持:将网站实时聊天、邮件、社交媒体等多渠道对话集中到一个收件箱。
- 帮助中心门户:发布帮助文章、常见问题解答等,让客户自助查找答案。
- 其他功能:涵盖协作、客户数据管理、集成、报告与洞察等多方面功能。
技术原理
文档未提及明确技术原理,推测其采用前后端分离架构,后端可能使用Ruby on Rails处理业务逻辑和数据存储,前端使用Vite构建用户界面,借助Docker实现容器化部署,利用Crowdin进行翻译管理。
应用场景
-
客户服务:客服团队通过Chatwoot集中处理多渠道客户咨询,提高响应速度和服务质量。
-
市场营销:利用客户数据和细分功能进行精准营销活动。
-
电商业务:结合Shopify集成,在平台内查看和管理客户订单。
-
chatwoot/chatwoot:开源实时聊天、电子邮件支持、全渠道服务台。Intercom、Zendesk、Salesforce Service Cloud 等的替代品。🔥💬
2.comfyUI
简介
ComfyUI 是强大且模块化的视觉 AI 引擎与应用程序,支持在 Windows、Linux 和 macOS 上运行。它提供基于图形/节点/流程图的界面,用于设计和执行高级稳定扩散管道,无需编写代码。
核心功能
- 支持多种操作系统和 GPU 类型,包括无 GPU 时使用 CPU 运行。
- 提供节点/图形/流程图界面,可创建复杂稳定扩散工作流。
- 具备异步队列系统和智能内存管理,优化工作流执行。
- 可加载多种模型和检查点,支持从生成文件加载完整工作流。
- 支持离线工作,有可选 API 节点连接外部付费模型。
- 提供丰富快捷键,方便操作。
技术原理
ComfyUI 基于稳定扩散技术,利用节点/图形/流程图界面将不同功能封装为节点,通过连接节点构建工作流。在执行时,仅重新执行工作流中发生变化的部分,实现高效计算。同时,采用智能内存管理,可在低显存 GPU 上运行模型。
应用场景
- 图像生成:设计和执行复杂的稳定扩散图像生成工作流。
- 视频处理:支持稳定视频扩散。
- 模型实验:通过节点界面快速实验不同模型和参数组合。
- 离线创作:无需联网即可进行创作。
2.fast-wiki
简介
FastWiki 是一个基于 .NET8、React 和 LobeUI 技术栈构建的企业级智能客服知识库系统。它旨在提供高性能、大规模的信息检索和智能搜索能力,并已成为 AIDotNet 组织旗下的开源项目,致力于为企业提供一站式 AI 应用平台解决方案。
核心功能
- 企业级智能客服知识库: 提供构建和管理企业知识库的能力,支持智能问答和客服自动化。
- 高性能信息检索: 优化大规模数据的检索效率,快速获取所需信息。
- 智能搜索: 利用深度学习和自然语言处理技术,实现精准的智能搜索功能。
- 内容管理: 支持知识内容的创建、编辑、分类和组织。
- API 接口: 提供开放接口,便于与其他系统集成。
技术原理
- 后端技术栈: 采用 .NET8 框架,提供高性能和跨平台能力。
- 前端技术栈: 使用 React 和 LobeUI 构建用户界面,提供良好的交互体验。
- 深度学习与自然语言处理 (NLP): 核心智能搜索功能依托微软 Semantic Kernel 进行深度学习和自然语言处理,实现对语义的理解和智能问答。
- 知识库管理: 底层实现高效率的知识存储、索引和检索机制,支持大规模知识数据的处理。
- 认证与授权: 利用 .NET 认证机制,提供安全的身份验证和访问控制。
应用场景
- 企业智能客服: 作为企业内部或外部的智能问答系统,辅助客服人员解答用户疑问,提升服务效率。
- 知识管理系统: 构建和管理企业内部的专业知识、产品手册、FAQ 等,方便员工快速查找信息。
- 技术支持平台: 为用户提供自助式技术支持,解决常见问题。
- 在线教育平台: 作为学习资料的知识库,提供智能检索和问答功能。
- 内容聚合与分发: 适用于需要对大量结构化或非结构化内容进行高效检索和展示的平台。
2.ragapp
简介
RAGApp 是一个开源的 Agentic RAG(检索增强生成)框架,旨在为企业用户提供一种简单便捷的方式,用于构建和部署 Retrieval-Augmented Generation 应用程序。它通过集成关键组件,极大地简化了复杂 RAG 系统的开发流程,使得在任何企业环境中都能高效利用 AI 技术。
核心功能
- 简化 Agentic RAG 应用构建: 提供了一种便捷的路径,使得开发者能够快速搭建 Agentic RAG 应用。
- 集成多模态组件: 无缝整合了向量数据库、大型语言模型(LLMs)以及聊天用户界面(Chat UI)。
- 支持可扩展 AI Agent: 促进开发可扩展的人工智能代理,以满足企业级的复杂需求。
- 开源框架: 作为开源项目,支持社区协作与持续发展。
技术原理
RAGApp 基于开源的 Python 框架构建,其核心在于实现了 Agentic RAG 范式。该框架通过高效地将检索模块与生成模块相结合,使得 LLM 在生成回复时能够访问并利用外部知识库中的信息。具体实现包括:
- 向量数据库集成: 利用向量数据库存储和管理大规模非结构化数据,通过嵌入技术实现高效语义检索。
- 大型语言模型(LLMs)交互: 作为核心生成单元,负责理解查询并根据检索到的信息生成相关、准确的响应。
- Agentic 工作流: 可能涉及规划、工具使用和推理等代理(Agent)机制,以增强 RAG 系统的智能化和自动化水平。
- 模块化架构: 采用模块化设计,方便各组件的插拔与扩展,支持定制化部署。
应用场景
- 企业知识库问答系统: 帮助企业员工或客户快速准确地获取内部文档、产品手册或常见问题解答等信息。
- 智能客服与支持: 构建能够理解用户意图并提供基于公司知识的专业回复的智能客服系统。
- 数据分析与报告生成: 通过结合结构化或非结构化数据,生成洞察报告或摘要。
- 研发辅助: 为工程师提供代码、技术文档等检索与生成支持,提高研发效率。
- 法律与合规查询: 辅助法律专业人士快速检索案例、法规,并生成相关摘要或分析。
- ragapp/ragapp: The easiest way to use Agentic RAG in any enterprise
- ragapp/ragapp:在任何企业中使用 Agentic RAG 的最简单方法
2.rasa-对话系统
简介
Rasa 是一个开源的机器学习框架,专门用于自动化基于文本和语音的对话。它使用户能够构建和部署功能强大的聊天机器人和语音助手,并支持连接到多种流行的消息平台,如 Slack 和 Facebook。
核心功能
- 自然语言理解 (NLU):解析用户输入,理解其意图和实体。
- 对话管理:管理对话流程,决定助手的下一步响应。
- 多平台集成:能够轻松连接和部署到 Slack、Facebook 等各种消息服务。
- 本地化部署:支持在本地部署,提供高度可定制的 NLU 和对话管理功能。
- 模型改进:Rasa X 等工具提供测试、用户交互分析和模型迭代优化的能力。
技术原理
Rasa 作为一个机器学习框架,其核心在于利用机器学习模型处理自然语言和管理对话状态。它主要包含两个核心组件:
- Rasa Open Source:提供底层的机器学习能力,包括 NLU 模块(用于意图识别和实体提取)和对话策略(用于根据对话历史决定下一步行动)。
- Rasa X:一个辅助工具,用于协作开发、测试、评估和改进对话模型,通过分析用户与助手的实际交互来优化性能。其技术原理基于深度学习或统计模型来处理语言数据,并根据预设的或学习到的策略来驱动对话流。
应用场景
- 客户服务自动化:构建智能客服机器人,处理常见问题咨询和用户请求。
- 企业内部助手:开发企业内部使用的助手,如HR机器人、IT支持机器人。
- 金融服务:构建专业的金融服务机器人,提供账户查询、交易咨询等服务。
- 在线教育:创建学习助手,回答学生问题或引导学习过程。
- 智能家居控制:作为语音控制接口,实现对智能设备的管理。
3.Chainlit
简介
Chainlit 是一个开源的 Python 软件包,旨在帮助开发者在几分钟内快速构建并部署生产级的对话式 AI 应用。它提供了一套简洁的框架,使开发者能够专注于核心的AI逻辑,同时处理用户界面、数据持久化和认证等复杂性。
核心功能
- 快速开发与部署: 允许用户通过几行Python代码迅速构建并启动对话式AI应用。
- 企业级认证集成: 支持与多种身份提供商集成,包括OAuth(如GitHub、Google、Azure、Okta、Amazon等),确保应用安全性。
- 数据持久化与分析: 提供数据收集、监控和分析用户交互的功能,以便更好地理解用户行为和应用性能。
- 多步骤推理可视化: 能够清晰展示AI生成输出的中间步骤和推理过程,有助于调试和理解AI决策。
- 多平台部署能力: 可将构建的AI应用部署为独立的Web应用、嵌入式助手、FastAPI服务或直接集成到Slack、Discord、Teams等消息平台。
- 广泛的生态系统兼容性: 兼容所有Python程序和库,并与LangChain、OpenAI、Autogen等主流AI框架和模型无缝集成。
技术原理
Chainlit 基于 Python 语言构建,核心在于其事件驱动的架构,通过 @cl.on_message 等装饰器捕获用户输入,并利用 cl.Message().send() 等函数进行响应。它提供了一个抽象层,简化了与大型语言模型 (LLM) 和 AI 代理的交互,允许开发者轻松集成如 LangChain、OpenAI 的 API 以及 Autogen 代理等。其设计支持模块化开发,可将AI逻辑与前端界面分离,并能以Web服务(如基于FastAPI)的形式提供后端支持。在数据管理方面,它实现了数据持久化机制,用于存储和分析用户交互数据。
应用场景
- 智能客服与问答系统: 快速搭建企业内部或对外的智能客服机器人、FAQ问答系统。
- AI助手与copilot: 开发嵌入到现有应用中的智能助手,提供实时帮助或建议。
- 对话式数据分析工具: 构建可以通过自然语言进行数据查询和分析的交互式应用。
- 教育与培训: 创建互动式学习伙伴或代码辅导机器人。
- 内部自动化工具: 开发用于简化工作流程、自动执行任务的内部AI机器人。
- 游戏与娱乐: 制作具有对话能力的虚拟角色或游戏NPC。
- 开发者工具: 为AI工程师提供一个快速原型开发和展示对话式AI应用的平台。
3.OpenChat
简介
OpenChat是一个开源的、面向日常用户的聊天机器人控制台,旨在简化大型语言模型的利用和定制化聊天机器人的创建与管理。它提供一个用户友好的平台,通过简单的两步设置过程即可构建全面的聊天机器人解决方案,并可作为集中枢纽来管理多个定制化机器人。
核心功能
- 简化LLM利用: 降低大型语言模型的部署和使用的复杂性。
- 定制化聊天机器人创建: 支持用户根据需求定制专属的聊天机器人。
- 多机器人管理: 提供一个统一的控制台来集中管理多个定制化的聊天机器人实例。
- 客户支持集成: 具备集成客户支持聊天小部件的能力,便于嵌入到网站或应用中。
- 快速部署设置: 通过简化的安装流程,实现快速部署和上线。
技术原理
OpenChat基于大型语言模型(LLMs)构建,采用模块化架构设计。其技术实现可能包括:
- 前后端分离架构: 代码仓库中包含
backend-server和llm-server等模块,表明其可能采用前后端分离的架构,后端负责业务逻辑和数据处理,llm-server则专门处理与LLM的交互。 - 容器化部署: 提及
docker-compose.yml文件,暗示系统支持通过Docker进行容器化部署,简化了环境配置和依赖管理。 - API集成: 通过标准API与不同的LLM服务进行交互,实现模型调用和结果处理。
- 用户界面: 提供直观的Web界面,供用户配置、管理和监控其聊天机器人。
- 开源性质: 作为开源项目,其代码可供社区审查、贡献和二次开发。
应用场景
- 个人AI助手定制: 非技术用户可以快速创建个人AI聊天助手,用于日常咨询、信息获取等。
- 企业客户服务: 中小型企业或开发者可以利用OpenChat部署定制化的AI客服机器人,处理常见的客户咨询,提供24/7在线支持。
- 教育与培训: 用于构建互动式的教学机器人,提供个性化的学习辅助。
- 内容创作辅助: 开发特定领域的聊天机器人,辅助内容创作者进行信息检索和灵感激发。
- 开发者工具: 为开发者提供一个快速原型设计和部署LLM应用的基础平台。
3.Verba
简介
Verba (The Golden RAGtriever) 是一个由Weaviate驱动的开源检索增强生成 (RAG) 聊天机器人应用,旨在提供一个端到端、精简且用户友好的界面,用于开箱即用的RAG功能。它是一个社区驱动的项目,致力于普及不同的RAG技术并展示Weaviate的强大能力。
核心功能
- 端到端RAG能力: 提供从数据摄取到生成响应的完整RAG工作流。
- 数据探索与洞察提取: 允许用户轻松探索数据集并从中提取有价值的洞察。
- 异步数据摄取与实时日志: 支持高效的数据导入,并提供实时的摄取过程日志。
- 灵活的文件管理: 支持单个文件或整个目录的上传,并提供文件选择界面,可对每个文件进行单独配置。
- 文档搜索与管理: 改进了文档搜索功能,允许为文档添加多个标签。
- 可配置的RAG组件: 提供对阅读器、分块器(chunkers)和嵌入器(embedders)的更多配置选项。
- 多部署选项: 支持本地、Docker、Weaviate云服务或自定义Weaviate实例的部署。
技术原理
Verba的核心技术原理基于**检索增强生成(Retrieval Augmented Generation, RAG)**范式,它结合了信息检索和生成模型。
- 向量数据库: 采用Weaviate作为其底层的向量数据库,用于高效存储和检索嵌入向量化的文本数据。
- 数据摄取与预处理: 通过异步摄取流程将各类数据(文件、URL等)导入系统,并进行**分块(chunking)和嵌入(embedding)**处理,将文本转化为高维向量表示。
- 语义搜索: 利用Weaviate的向量搜索能力,根据用户查询在向量数据库中检索语义相关的信息或文档片段。
- 生成模型集成: 将检索到的相关信息作为上下文输入给大型语言模型(LLM),由LLM生成更准确、更具上下文相关性的回答。
- 模块化架构: 设计上具有高度模块化,允许用户配置不同的阅读器(readers)、分块器(chunkers)和嵌入器(embedders),以适应不同的数据类型和RAG策略。
应用场景
- 企业知识库问答: 构建基于公司内部文档、规章制度的智能问答系统。
- 客服与技术支持: 为客户或技术人员提供快速、准确的解决方案和信息检索。
- 教育与研究: 学生和研究人员可以探索学术论文、教科书等大型数据集,快速获取所需信息。
- 数据分析与洞察提取: 帮助分析师从非结构化数据中快速提炼关键信息和趋势。
- 个人知识管理: 构建个人专属的智能知识库,方便回顾和查询笔记、文章等。
- 原型开发与研究: 作为RAG应用快速原型开发和不同RAG技术实验的平台。
3.Zep:AI 助手的长期记忆
简介
Zep 是一个专为大型语言模型(LLM)和聊天机器人应用设计的长期记忆存储系统。它能够帮助AI助手更有效地存储、管理和检索对话历史、用户数据和相关文档,从而提高AI的准确性和个性化程度。Zep 通过其独特的时间知识图谱(Temporal Knowledge Graph)机制,使AI能够理解和推理用户与业务数据的动态变化,实现持续学习和适应。
核心功能
- 长期记忆存储与管理: 为LLM和聊天机器人提供持久的对话历史、用户会话、用户元数据和文档存储。
- 上下文检索: 支持基于BM25、语义和图谱搜索的检索API,以获取与当前对话最相关的上下文信息。
- 时间知识图谱: 能够跟踪事实的变化、标记过时信息并保留历史记录,使AI能够对不断演变的状态进行推理。
- 用户与会话管理: 将用户、会话和聊天消息作为第一类抽象进行管理,支持“被遗忘权”等隐私合规操作。
- 与LangChain集成: 提供兼容LangChain的类(如ZepChatMessageHistory, ZepVectorStore, ZepMemory),便于集成到现有的LLM应用框架中。
- 文档向量搜索: 提供简便的文档向量搜索抽象,称为“Document Collections”。
技术原理
Zep 的核心技术在于其时间知识图谱(Temporal Knowledge Graph)。该图谱不仅存储事实,还能维护关于事实的上下文信息,并能推理状态变化。这意味着Zep能够记录和理解数据随时间如何演变,从而为AI提供数据溯源洞察。
- 多模态检索: 结合BM25(词频-逆文档频率)、语义搜索(通过嵌入向量)和图谱搜索,实现对相关信息的全面检索。
- 数据融合: 智能地将聊天消息和业务数据融合到知识图谱中,提供准确、相关的用户事实。
- 状态追踪: 标记过时的事实、追踪变化并保留历史记录,支持AI的持续学习和适应。
- 高度抽象: 将用户、会话和消息作为第一公民进行抽象,简化了聊天记忆的管理和隐私合规处理。
- 高性能: 被设计为快速响应,支持会话、用户和群组级别的图谱。
应用场景
- 智能客服与客户支持: 提高AI客服理解用户历史和偏好的能力,提供更个性化、连贯的服务。
- 个性化AI助手: 构建能够从用户交互和业务数据中持续学习并适应的个性化AI助手。
- 企业知识管理: 将企业内部的文档、对话和业务数据构建成可检索的知识图谱,辅助员工决策。
- 法律与合规: 通过“被遗忘权”等功能支持数据隐私和合规性要求。
- 智能推荐系统: 基于用户长期交互历史和偏好,提供更精准的推荐。
- AI Agent开发: 为复杂的AI Agent提供强大的记忆能力,使其在多轮对话和复杂任务中保持上下文连贯性和推理能力。
3.danswer
简介
Onyx(原Danswer)是一个连接公司文档、应用程序和人员的AI平台,提供功能丰富的聊天界面,可接入任意大语言模型。能让知识和访问控制在超40种连接器(如谷歌云端硬盘、Slack等)间同步,可在任何地方安全部署。
核心功能
- 提供安全的AI聊天功能,可接入任意大语言模型。
- 轻松设置与各类应用的连接器。
- 支持在团队工作处访问。
- 具备自定义深度学习模型用于索引和推理,可从用户反馈中学习。
- 有灵活的安全功能,如单点登录、基于角色的访问控制等。
- 提供知识管理功能,如文档集、查询历史、使用分析等。
技术原理
运用自定义深度学习模型进行索引和推理,结合多种信息检索方法(如StructRAG、LightGraphRAG等),利用大语言模型实现聊天交互,通过连接器与各类应用集成实现知识同步。
应用场景
- 团队内部知识查询与交流。
- 企业信息检索与研究。
- 客户服务与支持。
- 代码搜索与SQL结构化查询。
3.private-gpt
简介
PrivateGPT是一个可投入生产的AI项目,允许用户借助大语言模型(LLMs)对文档提问,即便在无网络连接的场景下也能使用,且完全私密,数据不会离开执行环境。项目提供遵循并扩展OpenAI API标准的API,可构建私密、上下文感知的AI应用,同时提供Gradio UI客户端用于测试API。
核心功能
- 高级API:抽象RAG(检索增强生成)管道实现的复杂性,包括文档摄取(内部管理文档解析、拆分、元数据提取、嵌入生成和存储),以及使用摄取文档上下文进行聊天和完成任务(抽象上下文检索、提示工程和响应生成)。
- 低级API:供高级用户实现复杂管道,包括基于文本生成嵌入,以及根据查询从摄取文档中返回最相关的文本块。
- 其他工具:提供Gradio UI客户端、批量模型下载脚本、摄取脚本、文档文件夹监控等工具。
技术原理
- API构建:使用FastAPI构建,遵循并扩展OpenAI API标准,分为高级和低级两个逻辑块。
- RAG管道:基于LlamaIndex,采用依赖注入方式解耦不同组件和层,使用LlamaIndex的抽象(如LLM、BaseEmbedding、VectorStore),便于更改实际实现。
应用场景
-
隐私敏感场景:适用于医疗、法律等对数据隐私要求高的行业,确保数据完全在用户控制之下。
-
离线场景:在无网络连接的情况下,仍可使用大语言模型对文档进行问答。
-
AI应用开发:为开发者提供构建私密、上下文感知AI应用的基础,可基于其API开发相关应用。
4.TurboRAG
简介
TurboRAG是一个新型检索增强生成(RAG)系统,通过预先计算和存储文档的键值(KV)缓存来加速检索增强生成过程,显著减少首次token输出(TTFT)的延迟,适用于对响应时间有严格要求的场景。
核心功能
- 加速检索增强生成:预计算和存储文档KV缓存,减少在线计算开销,降低TTFT延迟。
- 保持准确性:采用处理注意力掩码和位置ID的技术,并对模型微调,保证推理准确性。
- 易于集成:推理流程与标准RAG系统基本一致,方便集成到现有系统。
- 提高效率和吞吐量:减少资源消耗,支持更大批处理大小。
技术原理
- 预计算KV缓存:离线预先计算文档的KV缓存并存储,在线推理时直接使用,避免重复计算。
- 处理注意力掩码和位置ID:采用独立注意力掩码和重新排序的位置ID,适应预计算的KV缓存拼接,保持模型准确性。
- 模型微调:对预训练语言模型进行微调,使其适应新的注意力掩码和位置ID设置。
应用场景
-
实时聊天机器人:快速响应用户提问,提高交互体验。
-
客户支持系统:及时处理客户咨询,提升服务效率。
4.dialoqbase
简介
Dialoqbase是一款开源的工具,旨在帮助用户轻松创建个性化聊天机器人。它允许用户利用自己的专属知识库构建聊天机器人,从而提供高度相关且理解上下文的回复。该项目代码基于MIT许可,可免费用于商业用途。
核心功能
- 简易的聊天机器人创建: 提供友好的界面,简化聊天机器人的搭建过程。
- 基于自定义知识库: 允许用户导入并使用自己的数据作为聊天机器人的知识来源。
- 上下文感知回复: 结合先进语言模型,确保聊天机器人能够给出贴切且理解对话语境的响应。
- 高效向量搜索: 利用数据库系统实现知识库内容的快速检索。
技术原理
Dialoqbase的核心技术原理包括:
- 语言模型集成: 采用先进的语言模型(如LangChain框架)来处理自然语言理解和生成,确保回复的准确性和连贯性。
- 向量数据库: 借助PostgreSQL等强大数据库系统,实现知识内容的向量化存储和高效向量搜索,以快速匹配用户查询与知识库中的相关信息。
- 知识库管理: 安全保存并管理用户上传的知识库内容,作为聊天机器人响应的基础。
应用场景
- 企业内部知识问答: 构建针对公司内部规章制度、产品资料或FAQ的智能问答系统,提升员工效率。
- 客户服务与支持: 开发自动回复客户常见问题、提供产品信息或解决简单咨询的客服机器人。
- 个人知识管理: 创建个人专属的知识助手,快速查询和整理个人笔记、文档等信息。
- 教育辅导: 构建特定学科或课程的辅导机器人,帮助学生快速获取知识点。
4.knowledge_gpt
简介
Knowledge GPT 是一个可对文档提供准确答案和即时引用的项目,用户界面基于 Streamlit 构建,LLM 工具使用 Langchain。项目目前支持部分文件格式,后续有丰富功能的规划。
核心功能
- 为文档提供准确答案和即时引用。
- 支持用户上传文档进行相关操作。
技术原理
- 用户界面搭建采用 Streamlit 框架。
- 运用 Langchain 作为大语言模型(LLM)工具进行相关处理。
应用场景
-
对文档内容进行查询并获取准确答案及引用。
-
帮助用户处理上传的文档,获取相关信息。
-
mmz-001/knowledge_gpt: Accurate answers and instant citations for your documents.
4.rag-gpt
简介
RAG-GPT(Retrieval Augmented Generation - GPT)是一个结合大型语言模型(LLM)和检索增强生成(RAG)技术的系统。其核心目标是根据用户定制的知识库提供上下文相关的准确答案,从而实现快速而精确的信息检索。它通过学习用户提供的专有数据来扩展其知识范围,使其能够处理广泛的查询类型。
核心功能
- 基于定制知识库的问答: 能够从用户上传或指定的知识库中学习并提取信息,以回答相关问题。
- 上下文感知生成: 通过RAG技术,在生成回复时注入外部上下文信息,确保答案的准确性和相关性。
- 快速准确的信息检索: 旨在提供高效、精确的信息获取能力,减少幻觉并提高回答质量。
- 增强型LLM交互: 将LLM的生成能力与外部数据检索相结合,提升模型处理特定领域查询的能力。
技术原理
RAG-GPT的核心技术原理是检索增强生成(Retrieval Augmented Generation, RAG)。
- 外部知识注入: RAG不同于仅依赖LLM预训练知识,它在运行时从连接的数据源(如用户自定义知识库)中检索相关信息。
- 语义搜索: 系统利用语义搜索而非简单的关键词匹配来查找概念上相似的内容,即使词汇不完全匹配也能找到相关资料。这确保了检索到的信息是高度相关的。
- 上下文构建与提示: 检索到的信息被作为额外的上下文注入到LLM的提示中,指导LLM生成更准确、更具信息量的回答。
- LLM驱动生成: 增强后的提示随后被送入LLM进行文本生成,LLM结合其自身能力和检索到的外部信息,提供最终答案。
- 模块化架构: 通常包括数据索引(如Azure AI Search)、检索模块和大型语言模型(如Azure OpenAI Service中的GPT模型)等组件。
应用场景
- 企业内部知识管理: 构建基于公司文档、手册、报告的智能问答系统,提高员工获取信息的效率。
- 客户服务与支持: 创建能够从产品说明、FAQ、故障排除指南中检索信息的智能客服,提供即时、准确的客户支持。
- 特定领域专家系统: 在医疗、法律、金融等专业领域,结合特定知识库,构建提供专业咨询和信息查询的AI应用。
- 个性化内容推荐: 根据用户偏好和历史数据,从大量信息中检索并生成个性化的内容推荐。
- 教育与培训: 建立基于课程资料、教材的智能辅导系统,帮助学生快速获取学习内容。
4.ten_framework
简介
TEN(Transformative Extensions Network)是一个开源框架,旨在构建下一代实时多模态AI智能体,特别是专注于会话式语音AI智能体。它被誉为全球首个真正的实时多模态AI智能体框架,强调高性能、模块化和低延迟的特性。
核心功能
- 实时多模态交互:支持构建能够进行实时语音、视觉和虚拟形象(avatar)交互的会话式AI智能体。
- 自然对话能力:使AI智能体能够进行流畅自然的对话,提供接近人类的交互体验。
- 高度可定制性:允许开发者根据特定需求对AI智能体进行定制,满足多样化的应用场景。
- 低延迟通信:确保智能体响应迅速,提供即时反馈,尤其适用于实时会话。
- 生态系统组件:包含TEN Framework、TEN Turn Detection、TEN VAD(语音活动检测)、TEN Agent、TMAN Designer和TEN Portal等一系列开源工具和模块,覆盖从构建到部署的全生命周期。
技术原理
- 实时处理架构:框架核心设计理念是实现超低延迟的实时数据处理和响应,这对于会话式AI至关重要。
- 多模态融合:集成并处理来自不同模态(如语音识别、计算机视觉、情感分析)的数据,以实现更丰富和自然的交互。
- 模块化设计:采用模块化架构,使得各组件可以独立开发、测试和部署,提高系统灵活性和可维护性。
- 语音活动检测与轮次管理:通过TEN Turn Detection和TEN VAD等技术,精确识别语音活动和对话轮次,优化对话流管理。
- 高性能计算:底层设计可能利用高效算法和优化技术,确保在多模态数据处理和AI模型推理时保持高性能。
- 基于Agora等通信技术:得到Agora等实时通信技术支持,可能利用其SDK进行音视频流的传输和处理,保障实时性。
应用场景
- 智能客服与虚拟助手:开发能够进行实时语音对话、解答用户疑问或提供服务的智能客服系统和虚拟助手。
- 教育与娱乐AI:创建互动性强的教育伴侣或娱乐角色,通过语音和视觉进行多模态交互。
- 智能家居与IoT设备:为智能音箱、智能电视等设备提供实时、自然的语音交互能力。
- 机器人与自动化:赋能机器人具备实时会话能力,使其能够更自然地与人交流,执行复杂任务。
- 游戏内NPC:为游戏中的非玩家角色(NPC)提供高级会话AI,提升游戏沉浸感。
NativeMindExtension -AI本地助手
简介
NativeMind是一款本地AI助手,可连接Ollama本地大语言模型,在浏览器中提供AI功能,无需将私人数据上传到云端。具有本地优先、隐私为本、开源、支持企业级应用等特点,支持多种强大开源模型本地运行。
核心功能
- 总结网页内容:将长文章或报告总结为简洁摘要。
- 多标签页无缝对话:跨网页提问,保持上下文连贯。
- 本地网页搜索:在浏览器中完成搜索与回答。
- 沉浸式翻译:即时翻译整个网页并保持排版。
技术原理
通过连接Ollama,实现本地大语言模型(如DeepSeek、Qwen、Llama等)的运行,所有操作在本地设备完成,无需将数据发送到云端,利用本地算力进行数据处理和交互。
应用场景
- 个人使用:无需注册,无行为追踪,免费使用,可用于日常网页内容总结、对话、搜索、翻译等。
- 企业应用:适合企业日常流程,提供快速响应、本地运行、安全无忧的支持。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
