
AI Compass前沿速览:Nano Banana玩法教学、AgentScope、Hunyuan
AI Compass前沿速览:Nano Banana玩法教学、AgentScope、Hunyuan-MT-7B、HunyuanWorld-Voyager、AudioStory
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
flolife.me AI人生模拟器
flolife.me 是由 Flowith 团队开发的一款人工智能人生模拟器,旨在通过结合用户输入信息与先进AI技术,为用户生成多元化的虚拟人生体验。该模拟器也被称为“浮游人生”。

核心功能
- 角色创建与定制: 允许玩家输入姓名、性别、出生地等基本信息,并可分配智力、外貌、家庭背景和健康四项核心属性。
- 人生路径生成: 基于用户设定的角色信息和属性,结合AI模型生成角色的一生或多个人生版本。
- 交互式体验: 提供画布交互功能,增强用户在模拟过程中的参与感和沉浸感。
技术原理
flolife.me 的核心技术原理包括:
- 先进语言模型 (Advanced Language Models): 利用前沿的自然语言处理能力,模拟复杂的人生事件、决策及互动,生成丰富且连贯的叙事内容。
- 画布交互技术 (Canvas Interaction): 结合 Flowith 团队特有的画布交互技术,为用户提供直观且富有创意的界面,以可视化方式展现模拟人生进程。
- Nano Banana 技术: 集成“nano banana”技术(具体细节未披露,推测为某种特定的生成或模拟框架/库),以支持多元宇宙的生成和复杂场景的模拟。
应用场景
-
个人娱乐与模拟探索: 供用户体验不同人生选择和命运走向,满足好奇心。
-
创意内容生成: 为作家、游戏开发者或故事创作者提供灵感来源,生成独特的人物传记或情节。
-
决策辅助与情景推演: 辅助用户在虚拟环境中对人生重大决策进行初步模拟,从而更好地理解潜在结果。
Nano Banana 玩法教程大全
Nano Banana(又名Gemini 2.5 Flash Image):谷歌最新、最快速且最高效的模型。其原生多模态架构可同步处理文本和图像,解锁对话式编辑、多图像组合与逻辑推理等强大功能
- 文本生成图像:根据简单或复杂的文字描述生成高质量图像。
- 图像+文本编辑:上传图像并结合文本指令添加、移除或修改元素、改变风格或调整色彩。
- 多图融合与风格迁移:通过多张输入图像组合新场景或将某种风格迁移至其他图像。
- 迭代优化:通过多轮对话逐步调整图像细节,直至完美呈现。
- 文字渲染:生成包含清晰精准文字的图像,特别适用于标志、图表和海报设计。
热门玩法
- 将任意图片变成手办
prompt:turn this photo into a character figure. Behind it, place a box with the character’s image printed on it, and a computer showing the Blender modeling process on its screen. In front of the box, add a round plastic base with the character figure standing on.
将这张照片转化为一个角色形象。在其背后放置一个盒子,盒子上印有该角色的图像,盒子上方的电脑屏幕上显示Blender建模过程。在盒子前方添加一个圆形塑料底座,角色形象站立其上。


- 卡通变现实
prompt:Depict as a live big budget costume test on set, shot on film.
Variant Prompt: For easier additional editing.Depict as a live big budget costume test on set, shot on film against green screen.
描绘成在片场进行的大预算服装试穿,使用胶片拍摄。
变体提示:为了更轻松地进行额外编辑,描绘成现场的大预算服装测试,在片场拍摄,使用胶片对绿幕拍摄。

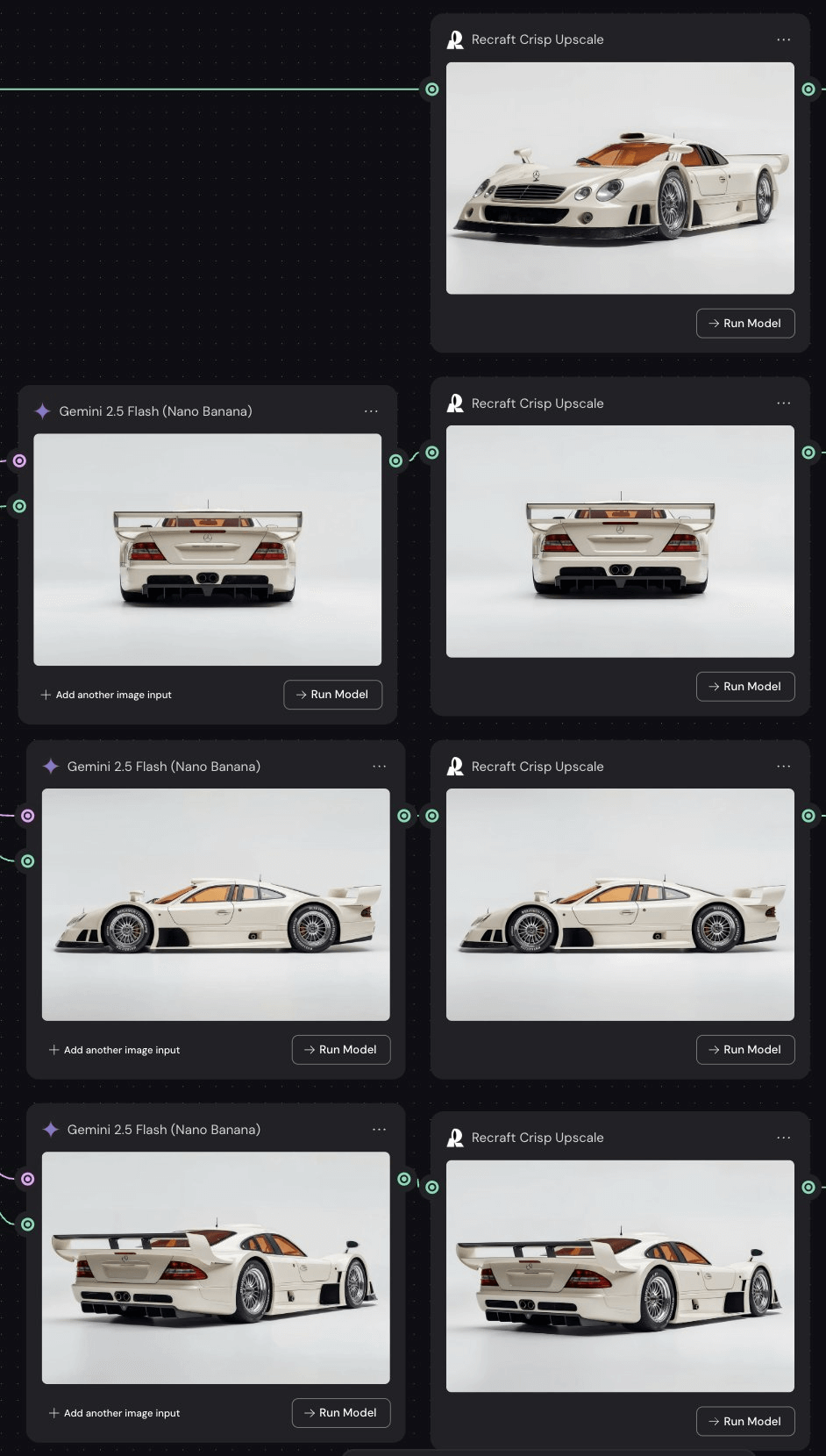
- 360度产品展示
prompt:This exact car in this exact environment.
Change Perspective: Perfect side angle view.
这辆汽车及其确切环境。
改变视角:完美的侧面角度视图
生成不同视角的图片后,用可灵2.1通过首尾帧生成视频。
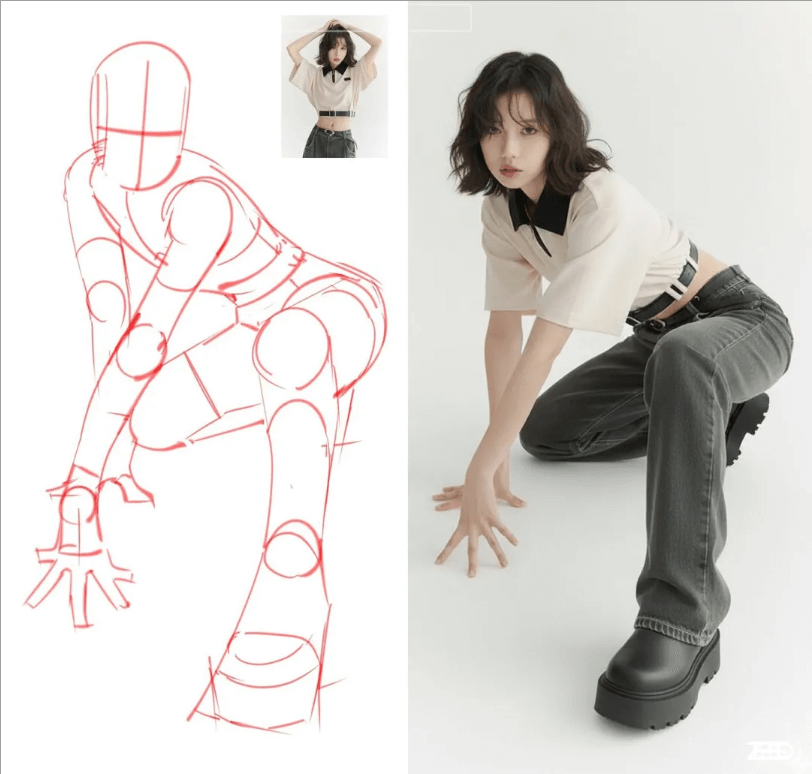
- 姿态参考
prompt:Model pose like the sketch.
提示词:模特姿势变得像草图一样。
- 图像位置参考
直接在图中标记位置,Nano Banana 就可以生成准确的图像。


- 漫画生成
- 准备角色参考的图片,三视图缺一不可。

-
标记分区
-
在图中加入提示词,生成漫画:

- 系列IP/动漫角色生成
prompt:First, please set up the basic color palette and the shadows and saturation.
提示词:首先,请设置基本色板和阴影与饱和度。
prompt:Next, please do the character model sheet.
接下来,请制作角色模型表。
prompt:Next, please provide the [basic action set].
接下来,请提供基本动作集。
prompt:Please give me the costume design set.
提示词:请给我服装设计套装。
prompt:Please make an expression sheet.
提示词:请制作表情表。






更多内容参考:https://mp.weixin.qq.com/s/jW4JKYzhAWq0DKHdU7T3gA
2.每周项目推荐
AgentScope 阿里多Agent开发框架
AgentScope 是一个以开发者为中心的框架,旨在通过支持灵活高效的工具化智能体与环境交互,来构建和部署基于大型语言模型(LLMs)的智能体应用。它提供统一的接口和高级基础设施,赋能智能体结合内在知识与动态工具使用,以应对复杂的现实世界任务。AgentScope 1.0 版本在此基础上进行了重大改进,致力于提供更全面的功能。
核心功能
- 灵活的工具化交互支持: 提供全面的机制,支持智能体与各种工具进行灵活且高效的交互。
- 统一接口: 为开发和部署智能体应用提供统一且简化的接口。
- 高级基础设施: 构建于先进的基础设施之上,确保智能体应用的稳定运行和高效开发。
- 实时操控(Real-time Steering): 允许用户在智能体执行任务过程中实时引导、纠正或重定向其行为,实现更具协作性的体验。
- 分组工具管理: 引入一种群组式的工具管理策略,将相关工具进行分组,以更结构化和高效的方式呈现和使用。
- 多智能体协作: 提供鲁棒的多智能体平台,支持构建复杂的协作式智能体系统。
技术原理
- 基于 ReAct 范式: AgentScope 的核心认知循环基于 ReAct(Reasoning and Acting)范式,使智能体能够进行推理并采取行动。
- 异步 I/O 取消机制: 通过利用
asyncio的取消机制,AgentScope 实现了实时操控功能,能够优雅地暂停正在进行的 ReAct 循环以响应外部中断信号。 - 模块化和可扩展设计: 框架被设计为模块化,抽象出构建智能体所需的基础组件,便于扩展和集成新的功能或模型。
- 分布式架构(推测): 考虑到其对多智能体和复杂应用的定位,可能采用分布式架构以支持大规模部署和并发操作。
应用场景
-
复杂智能体应用开发: 适用于开发需要与外部工具和环境深度交互的复杂智能体系统。
-
人机协作系统: 通过实时操控功能,可用于构建需要人类用户实时干预和引导的协作式AI系统。
-
自动化工作流: 结合分组工具管理,可用于构建涉及多个工具和步骤的自动化工作流,例如网络自动化任务。
-
多智能体仿真与研究: 作为灵活的多智能体平台,可用于多智能体系统、协作策略和分布式AI的研究和开发。
-
企业级AI解决方案: 其稳定性和可扩展性使其适用于构建企业级的、基于LLM的智能体解决方案。
-
arXiv技术论文:https://arxiv.org/pdf/2508.16279
Hunyuan-MT-7B – 腾讯混元翻译模型
腾讯混元-MT-7B(Hunyuan-MT-7B)是腾讯混元团队发布的一款轻量级开源翻译模型。该模型参数量仅为70亿,旨在提供高效、准确的机器翻译服务。尽管体量较小,但其性能据称可与一些闭源大型模型相媲美,致力于推动人工智能翻译的开放研究和应用。
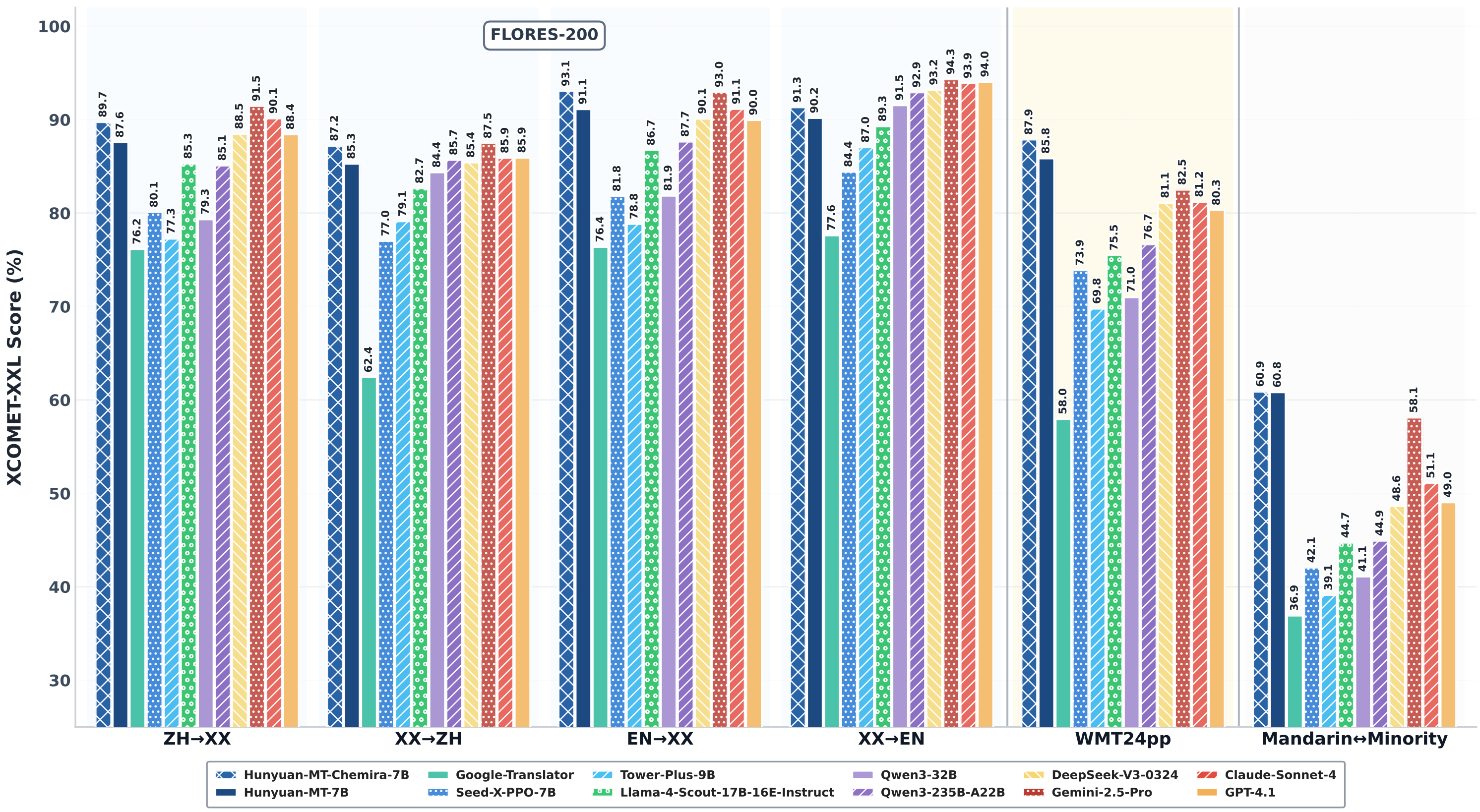
核心功能
- 多语言翻译: 支持33种语言的互译。
- 方言/民汉语言互译: 特别支持5种中国民汉语言/方言的互译。
- 高效翻译: 作为轻量级模型,能在保证翻译质量的同时提供较高的翻译效率。
- 模型组合: 除了基础的Hunyuan-MT-7B翻译模型,还包含一个集成了Hunyuan-MT-Chimera的增强模型,用于提升翻译表现。
技术原理
Hunyuan-MT-7B是一款基于Transformer架构的轻量级翻译模型,拥有70亿参数。该模型通过大规模多语言数据进行训练,以实现跨语言的准确映射。其设计理念强调在模型规模和翻译性能之间取得平衡,使其能够在资源受限的环境下运行。此外,该系列还提供了量化版本(如fp8),进一步优化了模型部署和推理效率。Hunyuan-MT-Chimera作为集成模型,可能采用了模型融合(ensemble)技术,结合多个模型的优势来提升整体翻译质量和鲁棒性。
应用场景
-
跨境交流与商务: 用于国际商务沟通、邮件往来、文档翻译等场景。
-
多语种内容创作与本地化: 辅助新闻、出版物、网站、应用程序等内容的快速翻译和本地化。
-
个人学习与旅游: 提供即时语言翻译支持,便于跨文化交流和学习。
-
教育领域: 作为语言学习辅助工具,帮助学生理解不同语言的文本。
-
研究与开发: 作为开源模型,可供研究人员在此基础上进行二次开发和创新,探索更多翻译技术与应用。
-
HuggingFace:https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
HunyuanWorld-Voyager – 腾讯世界模型
腾讯混元团队推出的HunyuanWorld-Voyager(混元Voyager)是业界首个支持原生3D重建的超长漫游世界模型。它是一个新颖的视频扩散框架,能够从单张图片生成用户定义的相机路径,并进一步生成与世界一致的3D点云序列,旨在重新定义AI驱动的空间智能。该模型基于HunyuanWorld 1.0构建,并已进行开源。
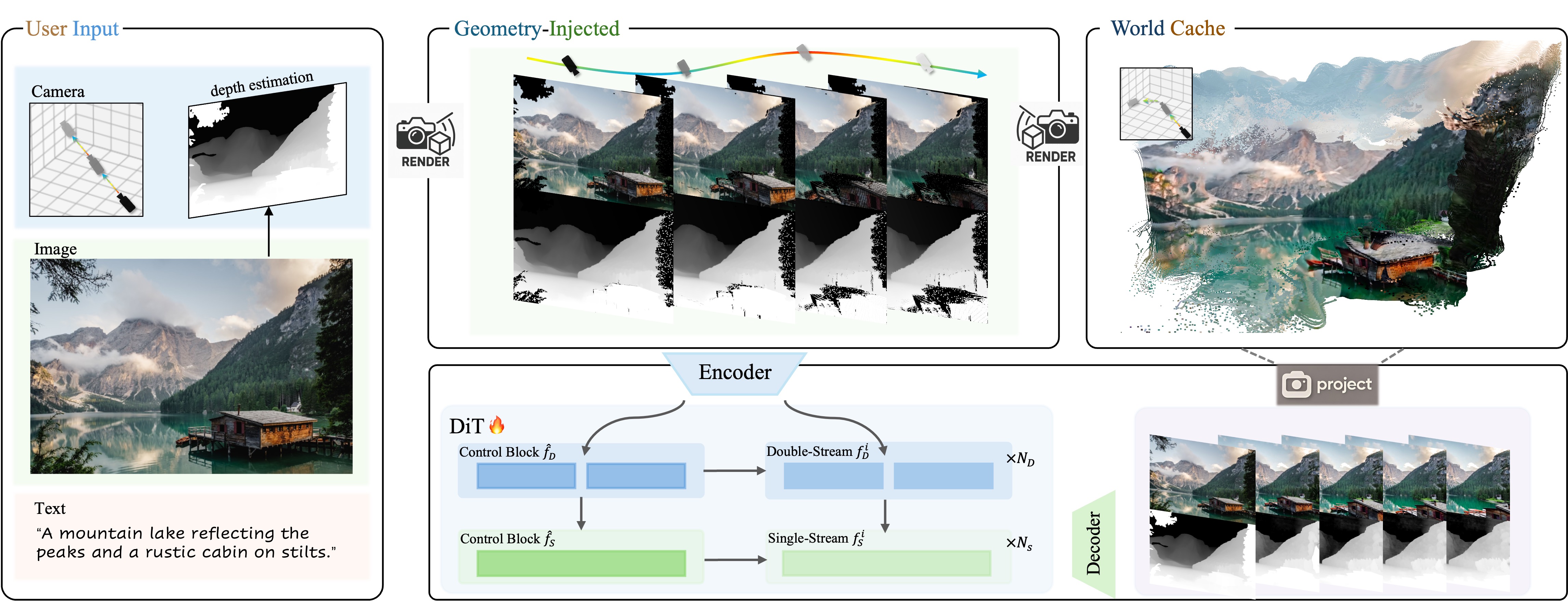
核心功能
- 原生3D重建与漫游世界生成: 能够进行超长距离的3D世界重建,并支持用户在生成的3D环境中进行漫游。
- 单图生成视频序列: 从一张静态图片生成与世界一致的、由相机路径控制的3D点云序列或RGB-D序列。
- 沉浸式3D世界创建: 支持从文本或图像条件生成沉浸式、可探索和交互式的3D世界。
- 物理渲染材质生成: 结合了PBR(Physically-Based Rendering)材质合成,能够生成具有电影级光照交互效果的逼真材质。
技术原理
HunyuanWorld-Voyager采用创新的视频扩散框架,其技术核心包括:
- 视频扩散模型: 利用扩散模型生成连贯的视频序列,实现图像到视频的转换。
- 原生3D重建: 不同于传统的2D生成再推断3D的方法,该模型实现了原生3D重建能力。
- 世界缓存方案与自回归视频采样: 引入高效的世界缓存方案和自回归视频采样方法,以支持世界重建和无限世界生成。
- 全景图生成与分层3D重建: 基于HunyuanWorld 1.0,通过全景图像生成、语义分层和分层3D重建等技术,实现高质量的360°场景级3D世界生成。
- 物理渲染(PBR)纹理合成: 采用物理渲染管线,通过物理驱动的材质模拟,生成具有逼真光照交互效果的纹理。
应用场景
-
虚拟现实(VR)与游戏开发: 用于快速生成沉浸式、可探索的虚拟场景和游戏世界。
-
电影与动画制作: 提供高效的3D资产创建和场景生成能力,加速影视内容生产流程。
-
数字孪生与空间智能: 在数字孪生、智能城市规划等领域,通过原生3D重建提供高精度的空间数据和模拟环境。
-
AI驱动的3D内容创作: 赋能创作者通过AI技术,以前所未有的效率和质量创建3D模型和世界。
-
Github仓库:https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager
-
Hugging Face模型库:https://huggingface.co/tencent/HunyuanWorld-Voyager
-
技术报告:https://3d-models.hunyuan.tencent.com/voyager/voyager_en/assets/HYWorld_Voyager.pdf
AudioStory – 腾讯音频生成模型
AudioStory是由腾讯ARC实验室开发的一项音频生成技术,旨在根据自然语言描述生成高质量的长篇叙事音频。它通过采用“分而治之”的策略,将复杂的叙事请求分解为有序的子任务,从而实现对长文本的有效处理和音频生成。该技术结合了大型语言模型(LLMs)的能力,以实现更优异的指令遵循能力和音频保真度。
核心功能
- 长篇叙事音频生成: 能够根据文本描述,生成连贯且具有叙事感的长篇音频内容。
- 自然语言描述到音频转换: 将用户输入的自然语言文本,直接转化为对应的音频故事。
- 分而治之策略: 将复杂的生成任务拆解成多个可管理的子任务,优化生成流程。
- 高音质与高保真度: 专注于生成高质量、高保真度的音频输出。
- 指令遵循能力: 能够更好地理解和遵循用户的文本指令,生成符合预期的音频。
技术原理
AudioStory的核心技术原理在于结合了大型语言模型(LLMs)的强大文本理解和生成能力与音频合成技术。它采用一种“分而治之”(Divide and Conquer)的策略,具体可能包括:
- 叙事分解: 将用户提供的长篇叙事文本,通过LLM进行语义分析和结构化分解,划分为多个逻辑上连续的短句或段落。
- 角色/情境感知合成: 对于分解后的每个子任务,LLM可能进一步推断出相应的情绪、语调、角色对话等信息。
- 多模态融合: 将文本信息(包括语义、情感、角色等)转化为音频合成模型可理解的参数,如音高、语速、音色等。
- 序列生成与衔接: 通过先进的深度学习模型(如Transformer架构的变体),逐段生成音频,并确保不同段落之间的自然流畅衔接,避免断裂感,从而实现长篇音频的连贯性。
- 音素到波形合成: 利用语音合成技术(如Tacotron、WaveNet或Diffusion Model等),将生成的声音特征转换为最终的音频波形。
应用场景
-
有声读物制作: 快速将小说、故事、新闻文章等文本内容转化为高质量的有声读物。
-
播客内容生成: 自动化生成播客节目的旁白、故事叙述或特定主题的音频内容。
-
教育与学习: 制作教学材料、历史故事、科学知识的音频版本,方便学生听觉学习。
-
游戏与动漫配音: 为游戏角色、动画片、虚拟人物提供快速、定制化的配音。
-
广告与宣传: 自动生成商品介绍、品牌故事等宣传音频。
-
无障碍辅助: 为视障人士提供文本转语音的辅助工具,提升信息获取的便利性。
USO – 字节内容与风格解耦与重组统一框架
USO(Unified Style and Subject-Driven Generation via Disentangled and Reward Learning)是由字节跳动智能创作实验室开发并开源的统一风格与主体驱动生成模型。该项目旨在解决传统上将风格驱动和主体驱动生成视为独立任务的局限性,通过一个统一的框架实现二者的融合,能够自由地将任意主体与任意风格结合,生成高质量的图像内容。
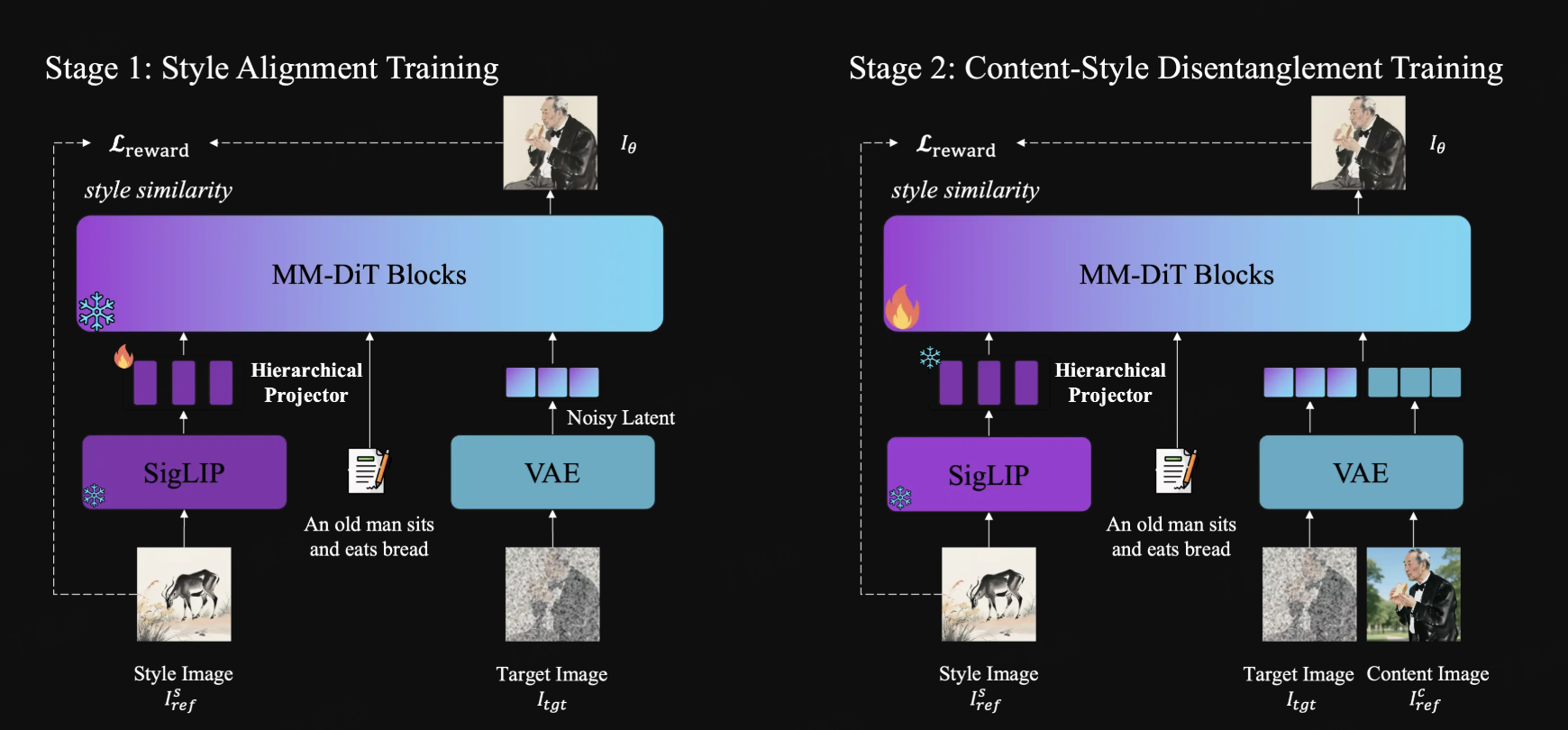

核心功能
- 统一图像生成: 能够在一个框架内同时进行风格驱动和主体驱动的图像生成。
- 高保真度输出: 确保生成图像在主体一致性、身份保持以及风格保真度方面达到领先水平。
- 自然人像生成: 特别优化生成自然、无“塑料感”的人像。
- 灵活组合能力: 允许用户自由组合不同的主体和风格,以适应多样化的创作需求。
- 性能评估基准: 发布了USO-Bench,作为首个联合评估风格相似性和主体保真度的开放基准。
技术原理
USO的核心技术在于其解耦与奖励学习(Disentangled and Reward Learning)机制。它通过精巧的算法设计,实现“内容”和“风格”的有效解耦和重组,从而克服了传统方法中风格和主体生成之间的内在矛盾。该模型构建在一个统一的生成框架之上,利用深度生成模型(如基于FLUX.1-dev的模型)进行图像合成。此外,它通过引入奖励学习进一步提升模型性能,确保生成结果的自然度和一致性。项目还进行了GPU内存优化,使其在消费级GPU(峰值显存约16GB)上也可运行。
应用场景
-
个性化图像定制: 用户可以根据个人喜好或特定需求,生成具有特定风格的自定义人像或场景图像。
-
数字艺术与创作: 赋能艺术家和设计师进行创新性的数字内容创作,探索不同风格与主题的结合。
-
虚拟形象生成: 用于创建逼真且风格多变的虚拟人物或数字分身。
-
娱乐与媒体: 在游戏、影视制作、广告等领域生成高质量的视觉内容。
-
学术研究: 作为开源项目,为计算机视觉和机器学习领域的研究人员提供了一个先进的基线模型和评估工具,推动相关技术的进步。
-
Github仓库:https://github.com/bytedance/USO
-
arXiv技术论文:https://arxiv.org/pdf/2508.18966
3. AI-Compass
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
 查看17道真题和解析
查看17道真题和解析